

















You plug into a deploy pipeline, run automated checks across critical user journeys, and return a plain-English verdict before users find the bugs. Start as a productized service, compound into a proprietary failure-intelligence layer, and grow toward a trust certification standard for AI-built software.
Realistic path to $60K–$150K MRR for a two-to-four-person team within a year.
The next bottleneck in software isn't code generation. It's trust.
Andrej Karpathy coined the term "vibe coding" in February 2025, describing a workflow where you "fully give in to the vibes, embrace exponentials, and forget that the code even exists." Collins Dictionary named it Word of the Year. Cursor's maker Anysphere hit a $9.9 billion valuation. Lovable crossed $100 million ARR in eight months. About a quarter of Y Combinator's Winter 2025 batch had roughly 95% of their code generated by AI. The vibe coding tools market is growing fast enough that multiple research firms are racing to size it, with estimates ranging widely depending on scope — but even conservative readings put it in the billions and accelerating.
Andrej Karpathy recently coined the term “vibe coding” to describe how LLMs are getting so good that devs can “give in to the vibes, embrace exponentials, and forget that the code even exists.”
— Y Combinator (@ycombinator) March 5, 2025
In this episode of the @LightconePod, the hosts discuss this new way of programming… pic.twitter.com/hSqzuwLsMb
Generation is largely solved. Verification is wide open. And the team that owns verification can build a real micro SaaS business selling to the exact builders flooding into this market — agencies and solo founders shipping AI-built apps with zero QA infrastructure. If you're looking for AI startup ideas that serve the people building with AI rather than competing with them, this is one of the strongest wedges available right now.
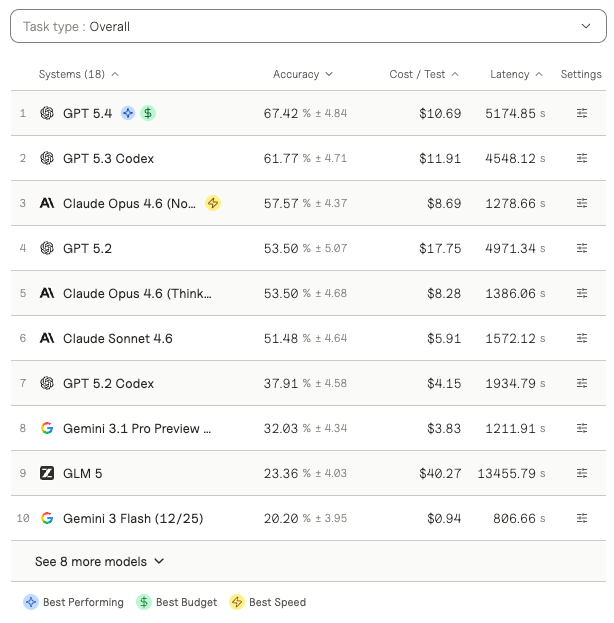
The Vibe Code Bench benchmark from Vals AI makes the gap tangible. It tests 100 web app specifications through 964 browser-based workflows comprising 10,131 substeps, evaluated against live deployed applications by an autonomous browser agent. Across 16 frontier models, the best achieved only 61.8% accuracy. Even at rank one, roughly one-third of workflows fail. Quality is no longer measured at the function or pull request level. It's measured across the end-to-end user journey.
The delivery data tells the same story. GitClear's 2025 research, analyzing 211 million changed lines of code from 2020–2024, found sharp declines in refactoring activity, rising code duplication, and increasing churn — with 2024 marking the first year on record where duplicated code exceeded refactored code. Harness's 2025 State of AI in Software Engineering reports that AI is speeding code delivery but shifting bottlenecks downstream into testing, deployment, and resilience. IDC's 2025 DevSecOps survey found that reviewers are encountering recurring security issues in AI-generated code at meaningful frequency. Google's 2024 DORA report corroborated the pattern: higher AI adoption was associated with a measurable reduction in delivery stability.
AI lowered the cost of generating product changes. It did nothing to lower the cost of verifying them.
That gap is the opportunity: build the trust layer for AI-built software.
The Wedge: An "AI Referee" for Prompt-Shipped Software
The product: a hosted service that plugs into your deployment pipeline, runs browser-based checks across your critical user flows, and returns a plain-English verdict before your users find the bugs.
"Your app passed 41 of 48 critical journeys. Billing failed on Safari mobile. Password reset regressed after the last prompt-assisted change."
Valuable on day one. You hand over a URL, seed credentials, and your top flows. That's it.

The first customers are obvious: solo SaaS founders using Cursor, Lovable, Bolt, Replit, v0, Windsurf, or Claude Code heavily. AI agencies shipping multiple client apps with minimal QA staff. Internal product teams whose developers lean on copilots but whose QA coverage is thin. These teams ship directly from prompts, diffs, or model-assisted edits. Their failure mode isn't "our compiler broke." It's "signup silently failed on mobile," "checkout works on desktop but not Safari," or "the CRUD table is visually broken after the AI changed a component hierarchy."
You don't need to educate these buyers that broken signup, payments, auth, or mobile UX matters. You only need to show them what broke last week and why they didn't catch it.
Why This Isn't Just "AI Testing" (And Shouldn't Be)
"AI testing" is not an empty market. Playwright offers a strong open-source execution layer for end-to-end testing across Chromium, WebKit, and Firefox. QA Wolf raised $57 million and promises 80% automated end-to-end test coverage in four months. Sacra estimated their ARR at $15–20 million in 2024 across roughly 130 customers. mabl is pushing GenAI-powered auto-healing. Applitools has a decade-long moat in visual AI trained on billions of app screens.

The bad version of this company is a thin wrapper around Playwright plus an LLM. That dies fast.
The good version is much bigger. Existing QA infrastructure assumes humans author stable test suites against stable codebases. AI-native development changes too quickly and too frequently for small teams to keep those suites current. Browser-agent benchmarks like Vibe Code Bench, WebArena, and WebVoyager evaluate the agents themselves — they don't tell you whether a specific shipped app is reliable enough for real users. So you get a strange gap: lots of tools for testing, lots of benchmarks for agents, no default referee for whether an AI-built product actually works.
The Moat: A Proprietary Failure Graph
Code generation used to be the scarce magic. It isn't scarce anymore. What remains scarce is trusted behavioral evidence at scale: which kinds of AI-generated changes break which kinds of product flows, under which stacks, on which devices, after which prompts. You are essentially building a behavioral verification of AI-built apps.

Run thousands of browser-based evaluations across AI-built apps and you're collecting far more than pass/fail results. You're building a proprietary failure graph. What prompt types tend to break authentication flows. Which frameworks are brittle around billing integrations. What UI mutations correlate with mobile layout regressions. How often model-generated CRUD features pass first-run validation. Which changes create accessibility failures versus logic failures. Which "working demos" collapse under cross-browser or viewport variation.
That corpus compounds. The more AI-generated apps your system evaluates, the more you move from testing into prediction.
The Real Product: Regression Risk Scoring for AI-Made Changes
The strongest version of this company behaves like a credit bureau for prompt-shipped software.
Here's the workflow:

Unlock the Vault.
Join founders who spot opportunities ahead of the crowd. Actionable insights. Zero fluff.
“Intelligent, bold, minus the pretense.”
“Like discovering the cheat codes of the startup world.”
“SH is off-Broadway for founders — weird, sharp, and ahead of the curve.”





