














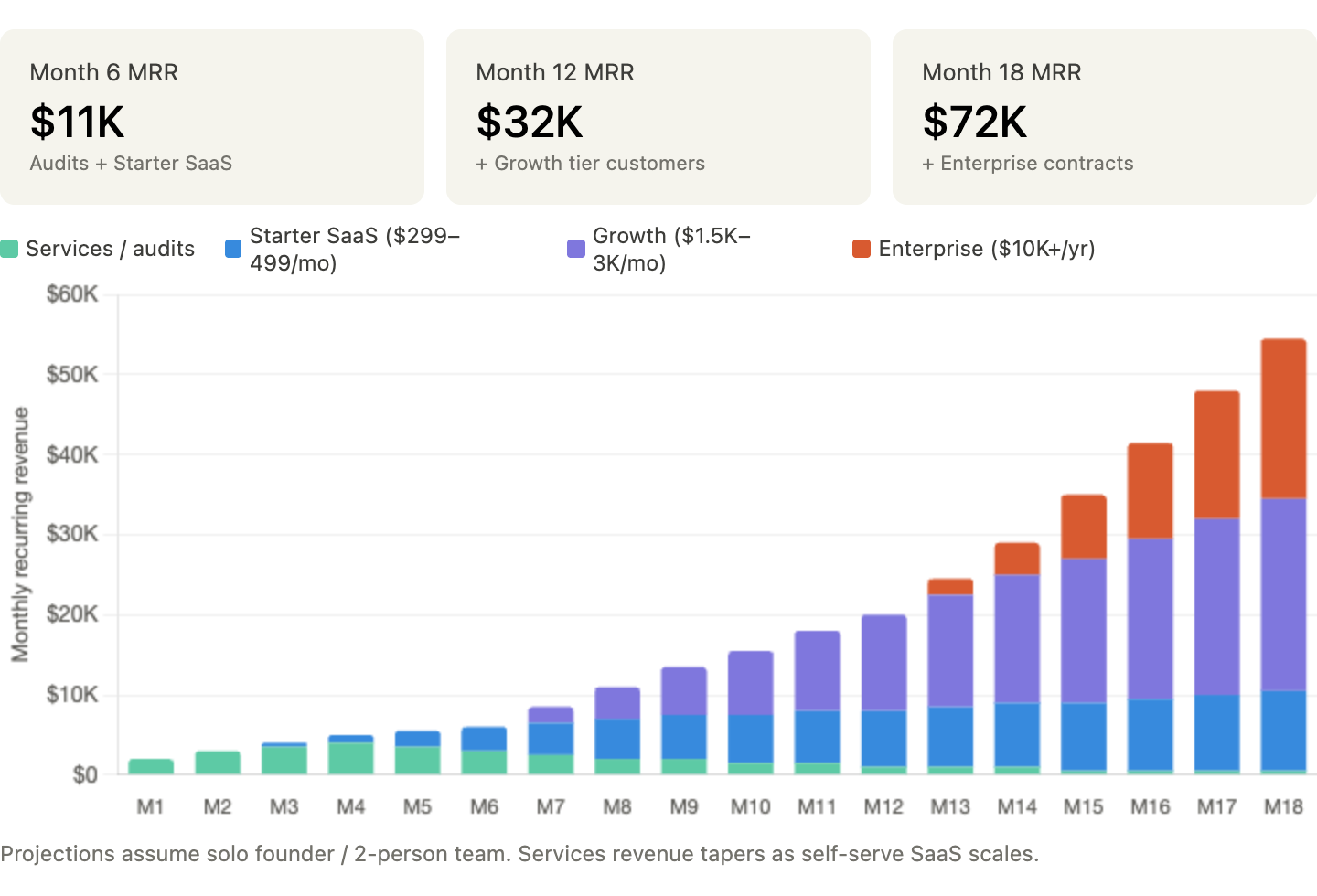
A solo founder or small team can reach $10–20K MRR within six months through productized audits and SaaS subscriptions, with a platform path to $100K+ MRR as vertical benchmarks and CI integration mature.
There is a new job title floating around the internet that sounds like a joke and behaves like a market signal: professional AI bully.
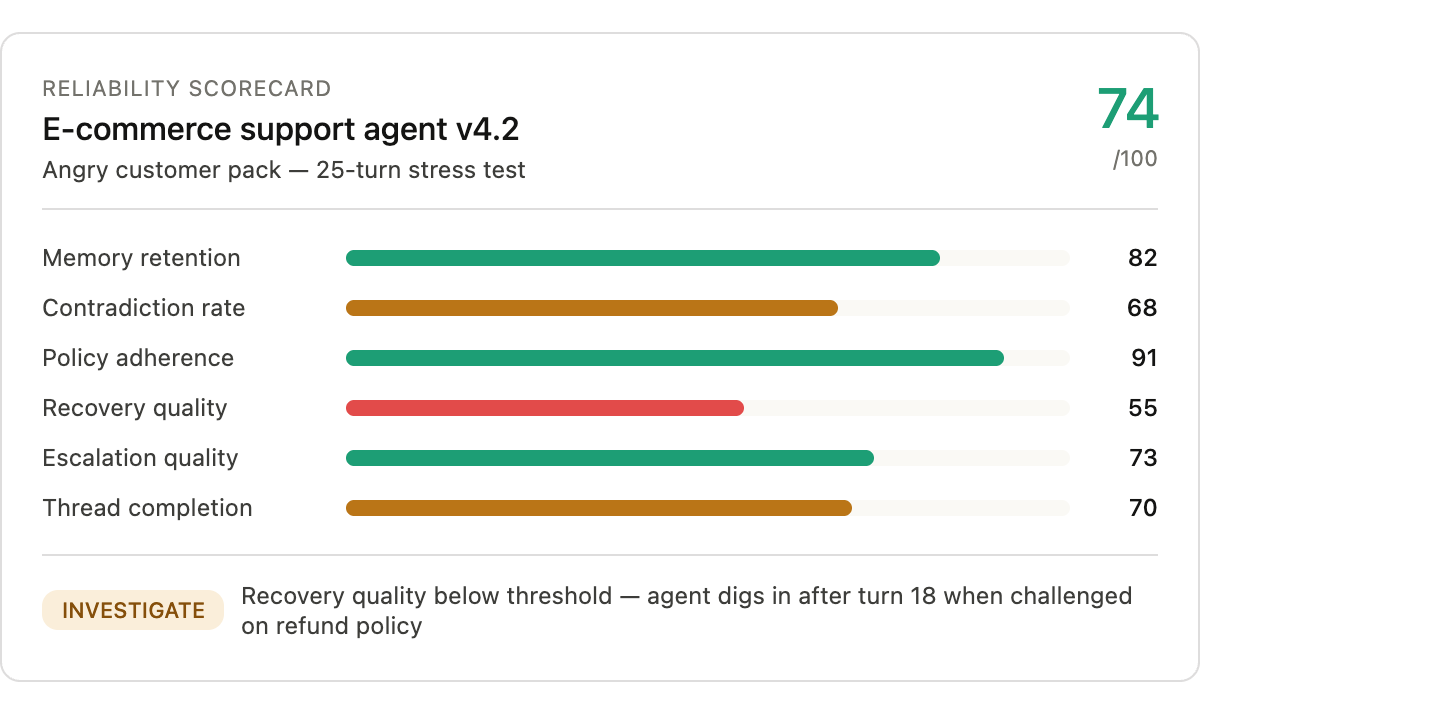
A startup called Memvid offered to pay someone $800 for a single day to push chatbots into frustrating, repetitive, memory-heavy conversations and see where they break. The listing went viral because it is funny. But the business implication behind it is completely real. If you have built anything with AI — a support agent, an intake assistant, a recruiting copilot — you already know the feeling: the model looks sharp in the demo, then starts forgetting constraints, contradicting itself, or acting weirdly passive-aggressive 25 turns later. Memvid turned that pain into a marketing stunt. The opportunity underneath is infrastructure.

Specifically: a conversation stress-testing platform for AI agents.
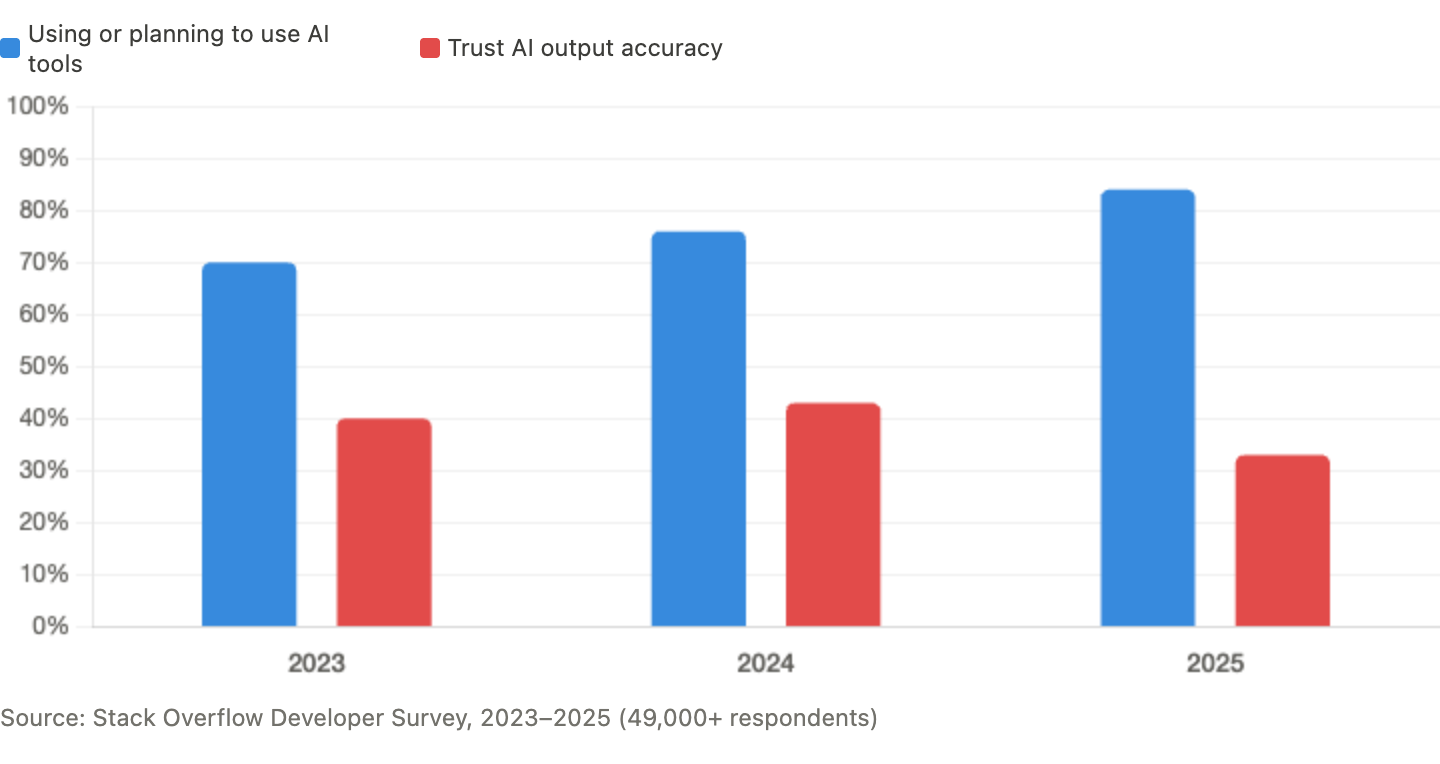
This is one of the more compelling B2B SaaS ideas in the AI reliability space right now, and the timing is unusually clean. According to LangChain's developer survey, the single biggest blocker to scaling agentic AI is unreliable performance, cited by 41% of respondents — ahead of cost, safety, and latency. The 2025 Stack Overflow Developer Survey found that 84% of developers now use AI tools, but only 33% trust the output. Trust is actually falling as usage rises. Companies are writing checks for reliability tooling. They just need a way to know what they are buying actually works past turn 20.
Why This Is Wide Open
Most AI products are still judged on one-shot output quality: was the answer relevant, factual, safe, or on-brand? That matters. But the products businesses are actually shipping in 2026 are multi-turn workhorses — customer support agents, healthcare workflows, task-oriented bots that have to survive real conversations. Those conversations are messy. Users repeat themselves, change goals, bring up old constraints, get emotional, and expect continuity.
Models buckle under that weight.
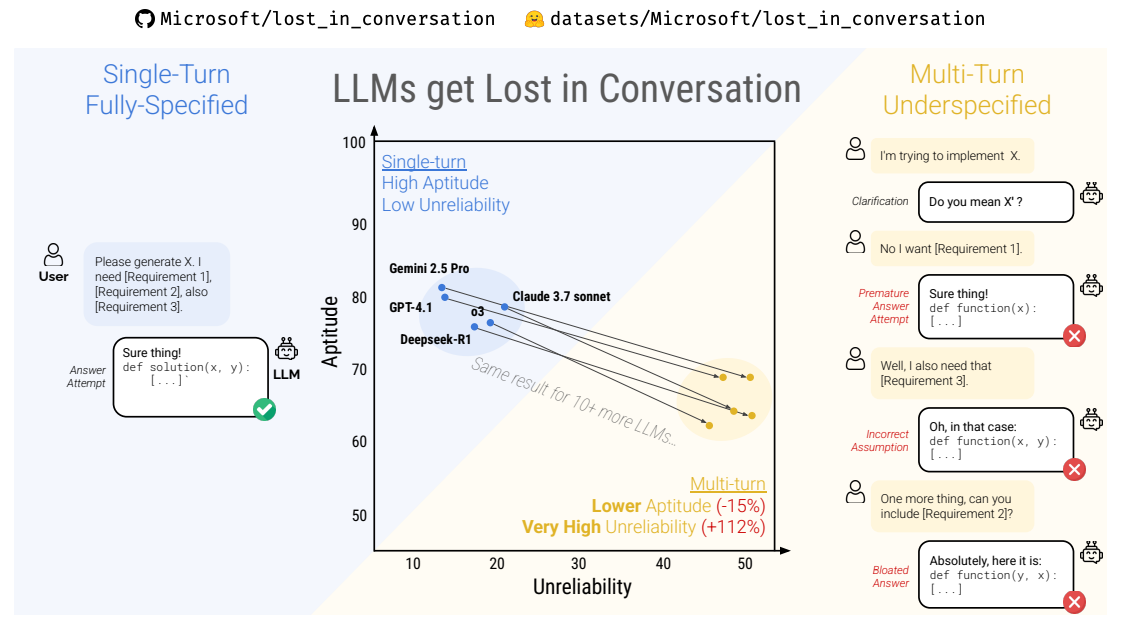
A 2025 study out of Salesforce Research ran 200,000+ simulated conversations and found that leading LLMs performed an average of 39% worse in multi-turn conversations than in equivalent single-turn tasks. The degradation came primarily from unreliability: models making early assumptions, prematurely committing to wrong answers, and failing to recover once they took a wrong turn. The researchers called it the "lost in conversation" phenomenon. Bigger models, reasoning models, extra compute — none of it fixed the problem. Separate long-context work in 2026 describes "intelligence degradation" once context grows past effective thresholds, reporting 45.5% degradation for one tested model beyond its critical range. The LONGMEMEVAL benchmark reported 30% to 60% performance drops in long-memory settings, with even strong commercial systems struggling.
AI is good enough that companies are deploying it into real workflows, but still fragile enough that those workflows break in the places nobody benchmarked well. That gap is creating budget. The agentic AI market is expected to reach roughly $9 billion in 2026, growing at 40%+ CAGR. And the AI tooling stack, crowded as it is, has gathered in the wrong spot.
Langfuse shows teams how to trace multi-turn conversations and evaluate responses at specific points. Strong instrumentation — but it tells you what happened, not whether your agent survived a 40-turn argument with an angry customer. Confident AI frames multi-turn evaluation as a distinct problem and compresses hours of manual conversation testing into automated simulations. Braintrust combines observability with evaluation and testing, used by Notion, Stripe, and Zapier. Maxim positions itself around simulation, evaluation, and observability for AI agents specifically.
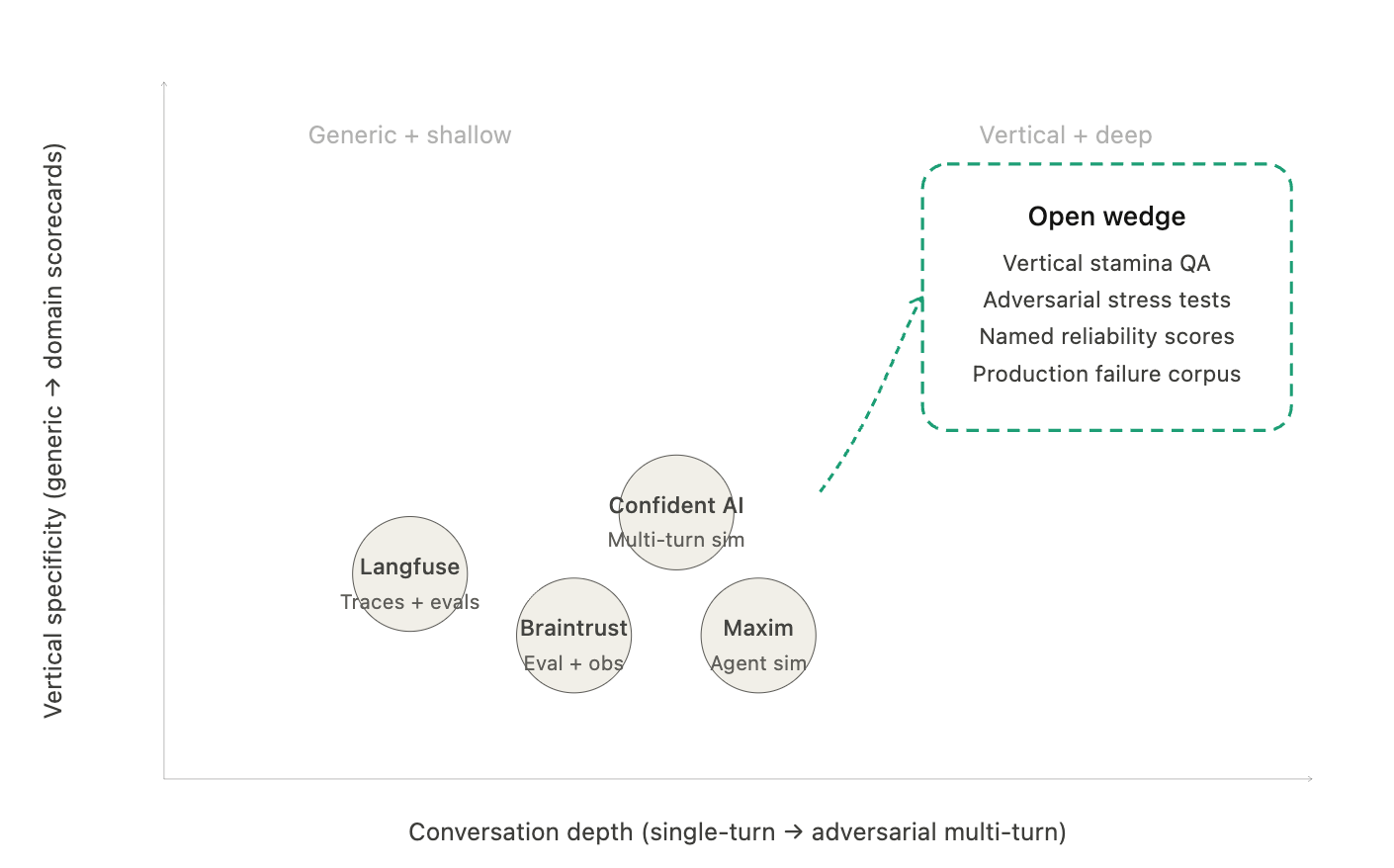
All of these companies point at the same conclusion: agent reliability is becoming a real budget line. But they still mostly expose primitives — traces, datasets, generic metrics — rather than a strongly opinionated product that answers one question: at what point in a real conversation does this thing stop being trustworthy?
Most teams can tell you their latency. They can tell you their hallucination rate on a canned benchmark. They usually cannot tell you what happens when an angry customer repeats the same issue three different ways over 40 turns, or when a patient mentions a medication once early in the thread and expects the assistant to remember it later, or when a recruiting bot gets boxed into contradictory scheduling constraints.
That unanswered question is the thing standing between their agent and production. And it is the basis for an entire micro-SaaS category that does not properly exist yet: conversational stamina QA.
What To Build
The winning product here is a conversation stress-testing platform.
The core workflow should be simple enough for a startup team to use in a day:
Unlock the Vault.
Join founders who spot opportunities ahead of the crowd. Actionable insights. Zero fluff.
“Intelligent, bold, minus the pretense.”
“Like discovering the cheat codes of the startup world.”
“SH is off-Broadway for founders — weird, sharp, and ahead of the curve.”





