















A focused product serving 20 brokers at $1,500/month reaches $30K MRR in 12–18 months, with insurance verticals commanding higher price points. The moat is domain-specific validation logic and accumulated edge-case data, not extraction quality.
Frontier AI can write code, draft memos, and reason through corporate strategy — yet businesses still lose hours and money to basic document chaos. PDFs were built to preserve visual layout, not clean machine-readable structure, and even advanced models misread columns, confuse footnotes with body text, break tables, and hallucinate missing values when a document is ugly enough. A 2025 benchmark by Applied AI tested 17 parsers across 800+ real-world documents and found that a parser can score 75% on text extraction while scoring just 13% on structure recovery. Reading the document and understanding it are still two different problems — and that gap is one of the more overlooked AI startup ideas in B2B right now.
The real economy runs on cursed documents. Insurance submissions, loss runs, freight bills of lading, proof-of-delivery packets, permit applications, invoices, medical records, legal exhibits, scans, faxed forms. These aren't edge cases. They are the workflow. The intelligent document processing (IDP) market reflects it: valued at roughly $2–3 billion in 2024–2025, growing at a compound annual rate in the high twenties to low thirties, and projected by multiple research firms to reach $20–40+ billion by the early 2030s. Databricks' principal research scientist put it bluntly: "It's a common assumption that parsing PDFs is a solved problem, but in reality, it isn't." Independent analyses consistently estimate that around 80% of enterprise data remains locked in unstructured formats — emails, scanned documents, PDFs, logs — that AI systems still struggle to process accurately.
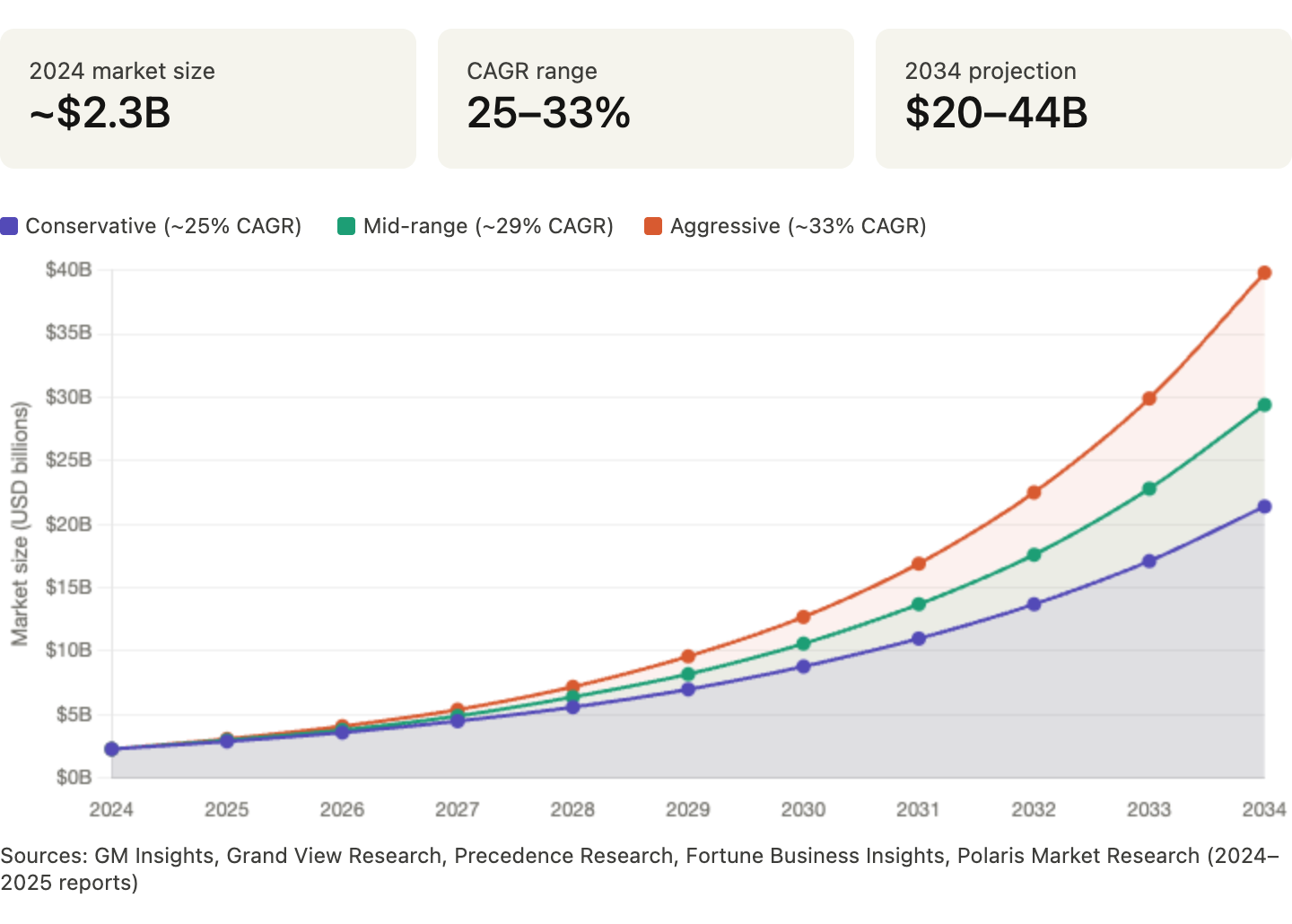
The market isn't asking whether companies will pay to solve this. They already do. The question is whether you can wedge a sharper product into a painful document workflow before a flood of generic "AI OCR" and LLM-powered document tools commoditize the space. The answer depends on depth, not breadth.
Why This Is a Real Heist
Most founders see PDF parsing as a technical nuisance. The better frame is operational leverage.
When a team can't trust incoming documents, they build an entire shadow workflow around that distrust: manual re-entry, spreadsheet reconciliation, exception chasing, email threads, delayed billing, slower underwriting, audit exposure. In freight, manual BOL processing takes 30–60 minutes per document, and ocean carriers issue approximately 45 million bills of lading annually. In insurance, underwriters spend up to 40% of their time manually processing and analyzing loss run reports. All of that time burns on paperwork instead of actual risk assessment.

You aren't inventing demand. You're selling relief into an existing operational wound. And your real competition isn't other software — it's headcount. You're competing with the ops teams' existing spreadsheet queues and the three full-time employees a mid-size broker keeps on staff just to cross-check paperwork.
The mistake would be building "yet another PDF extractor." Extraction alone gets commoditized. Open-source tools improve. APIs get cheaper. General models get better. The durable play is the trust layer around extraction — verification, reconciliation, and routing that makes the output operationally usable. That's where this becomes a real micro SaaS idea with serious pricing power, not a feature that gets absorbed into someone else's platform.
The Real Product Is a Trust Layer
The strongest version of this business is a vertical document operating system: ingest, classify, repair, extract, verify, route, audit. That's the long-term platform. The wedge is much narrower. Pick one ugly document category in one vertical and become the system that turns it into structured, reviewable, provenance-backed data.
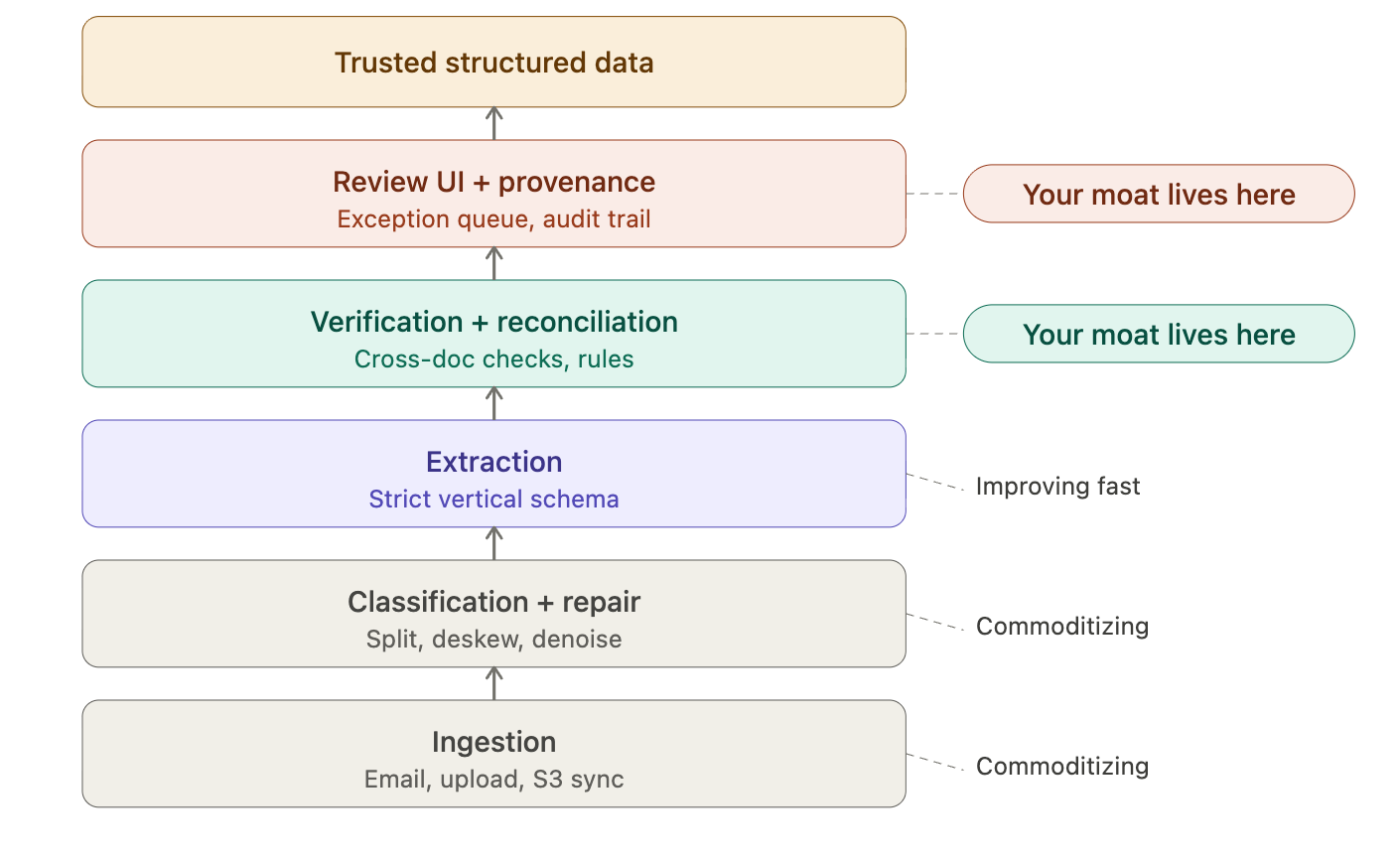
Customers don't actually want "AI that reads PDFs." They want a system that says: This packet has been split correctly. These fields were extracted. These numbers were cross-checked. These three lines failed validation. Here is the exact page and bounding box where each value came from. A human can fix the exceptions in two minutes.
That moves you from "tool" to "control point." Reading gets cheaper every year. Verifying, reconciling, and routing correctly inside a messy workflow is still scarce — and that's where margins and stickiness live.
Where the Play Is
The best opportunities share a few traits: high-frequency document classes, real pain, semi-standardized formats, and downstream money that only moves after the document is trusted. Three wedges stand out.
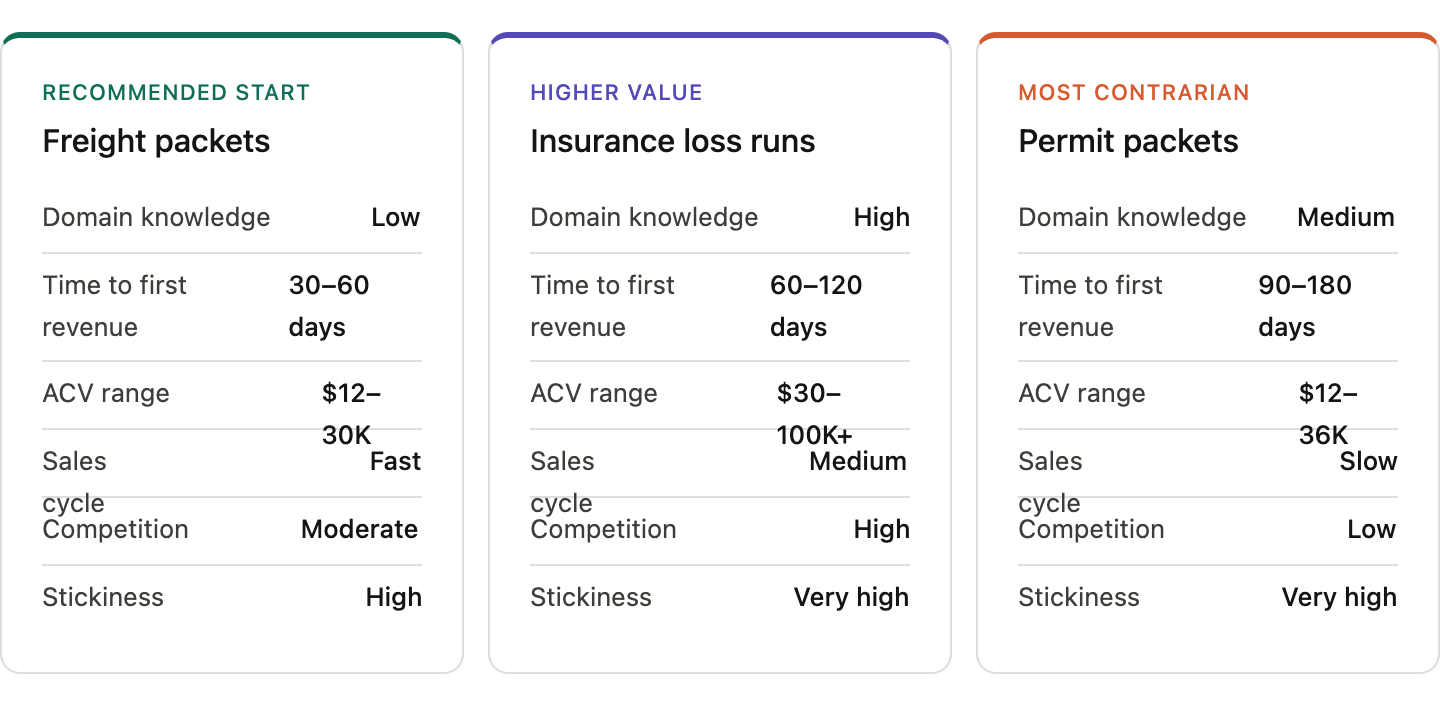
1. Freight Packet Verification
Probably the cleanest small-team wedge, and the recommended starting point.
A freight broker or 3PL receives a bundle for every shipment: bill of lading, proof of delivery, freight invoice, maybe a rate confirmation, sometimes customs or accessorial documentation. The problem isn't extracting a few fields. It's checking whether the documents agree. Are the lane, shipper, consignee, weights, references, dates, and charges consistent? Is anything missing? Can this be billed confidently?

The stakes are concrete. Freight audit vendors and industry specialists consistently report that billing errors — wrong fuel surcharges, phantom accessorial charges, weight disputes, duplicate invoices — drain several percent of a company's total transportation budget. Estimates typically land in the 3–8% range, and the freight audit and payment market itself is growing at a high-single to low-double-digit CAGR as shippers scramble for cost control. Each invoice contains dozens of line items with complex rate calculations, carriers use different formats and calculation methods, and manual verification at scale is practically impossible.
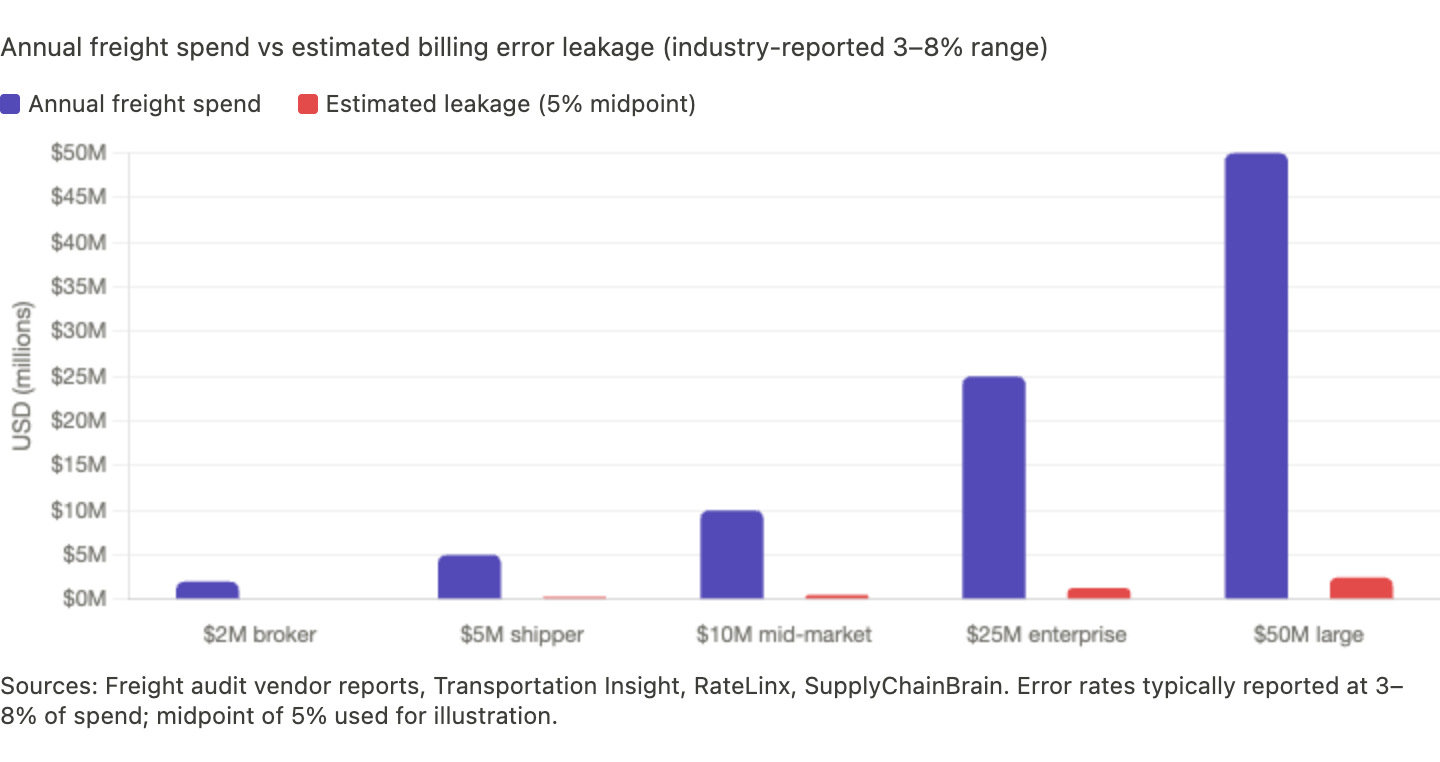
A narrow product punches above its weight here. You ingest the packet from email or folder drop, classify the documents, extract key fields, reconcile them against each other and against the TMS, then surface only the exceptions. The output isn't a spreadsheet. It's a shorter queue and faster billing — a document automation tool built for freight ops teams, not a generic AI demo.
The pain is frequent, the value is legible, the document classes are repetitive enough to learn, and the ROI writes itself. You're selling faster billing, fewer disputes, fewer manual touches, and cleaner audit trails.
A concrete example: A mid-size freight broker processes 500 shipments per week. Each packet requires 15–30 minutes of manual reconciliation. That's 125–250 hours of staff time weekly — roughly three to six full-time employees doing nothing but checking paperwork. A product that cuts that by 70% pays for itself inside 30 days.
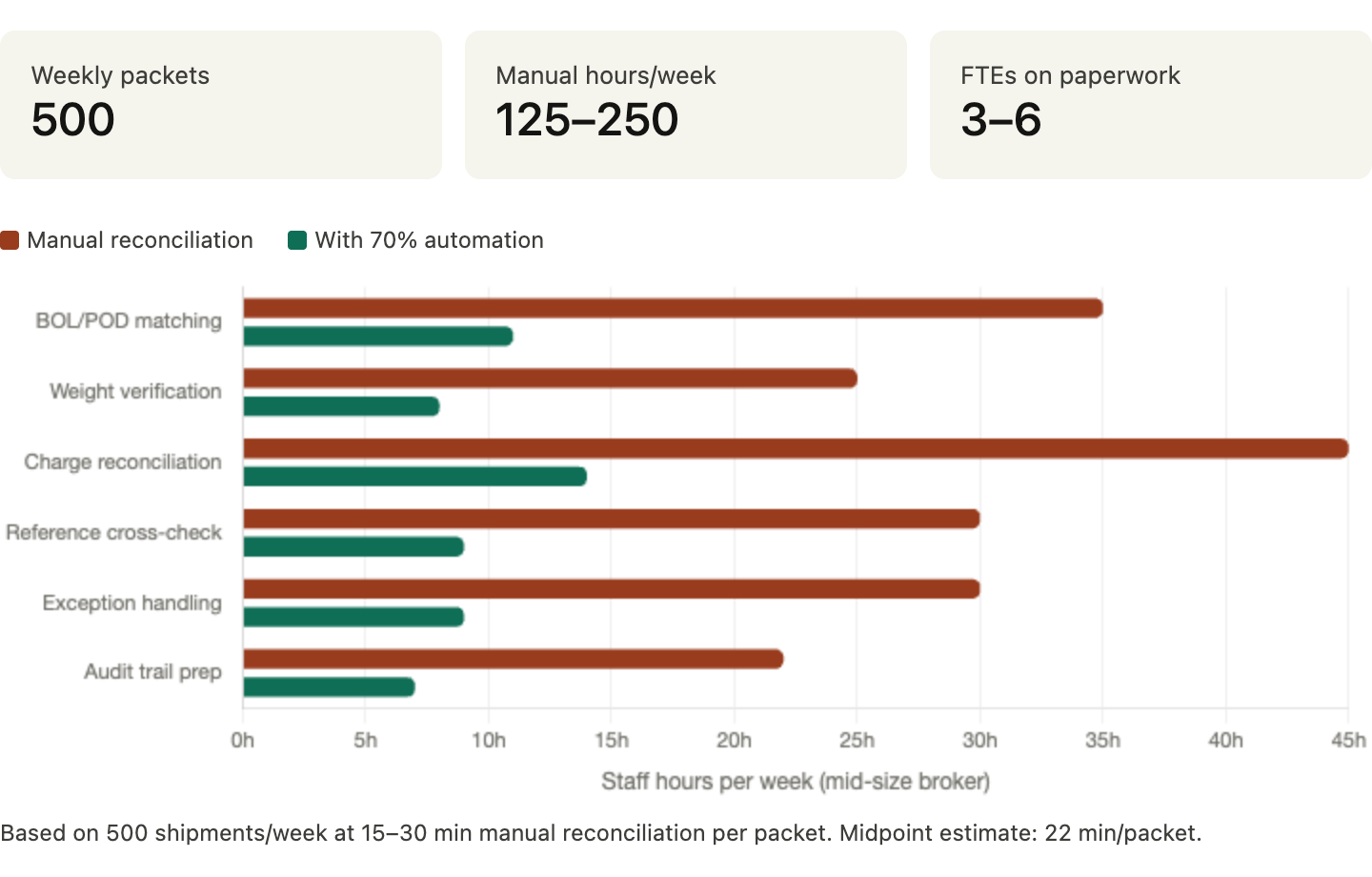
Execution risk here is manageable: integrating with TMS platforms and handling carrier format variation. Stay disciplined about which modes and lanes you support first, and expand from there.
2. Insurance Loss Run and Submission Normalization
Higher value, more domain knowledge required.
Insurance underwriting intake is document chaos. Submissions can contain ACORD forms, supplemental applications, loss runs, schedules, PDFs exported from carrier systems, broker-produced summaries, and random attachments. Much of the real work isn't deep actuarial brilliance — it's prep. Someone has to normalize a carrier-specific mess into a usable schema before the underwriter can even begin thinking.
Loss runs are especially attractive because they're painful, repetitive, valuable, and structurally similar enough to productize once you've seen enough variants. Every insurance carrier uses a different format. The same carrier can use different layouts for different coverage types. Individual documents can run for dozens of pages and span multiple years. One case study described an underwriting platform serving hundreds of underwriters across different verticals where manual extraction of loss run data became the bottleneck limiting what the platform could offer. The company ultimately built over 300 extraction templates just to handle carrier format variation.

The product here isn't "summarize the loss run." It's: convert any loss run into a standard schema, catch inconsistencies, flag missing periods or pages, and hand the underwriting team something immediately usable. AI vendors in the space already claim 90% faster processing at 98% accuracy, which tells you the category has established buyer expectations and validated willingness to pay.
The trade-off: insurance is a top adopter of document AI, so you enter a more competitive space that expects maturity. You'll likely compete with established underwriting platforms that are already bolting on document AI modules. The defense is going narrower than they will — one coverage type, one document class, better exception handling than the bolt-on can deliver.
For a smaller builder, workers' comp is a strong entry point since claim history is the primary predictor of future risk for physical-labor businesses. Expand from there.
3. Permit Packet Normalization
The most contrarian wedge on this list.
Municipal and construction permitting is full of packet assembly, checklist verification, locality-specific requirements, and back-and-forth over missing or misfiled documents. Less glamorous than logistics or insurance, which is exactly why it's interesting.

The pain is real and the money is moving. PermitFlow raised $54 million to build AI-powered permit management, reporting that builders using their platform shortened timelines by up to 60% and reduced administrative workloads by 90%. They've processed over $20 billion in construction value.
The moat for a smaller builder comes from encoding local rulebooks and packet logic over time. Every municipality has its own requirements, forms, and review processes. The sales cycle may be slower and the buyer universe more fragmented — contractors, expediters, developers — but once a permit specialist trusts your system to make packets "submission-ready," the product becomes deeply embedded. This is the closest path from "annoying workflow tool" to "industry infrastructure."
The Moat
You don't build a moat here by claiming magical AI. You meticulously build it through four layers:

Unlock the Vault.
Join founders who spot opportunities ahead of the crowd. Actionable insights. Zero fluff.
“Intelligent, bold, minus the pretense.”
“Like discovering the cheat codes of the startup world.”
“SH is off-Broadway for founders — weird, sharp, and ahead of the curve.”





