

















A single 10-person brokerage paying $500/seat is $60,000 ARR. Land 50 customers and you're at $3 million. The moat isn't your model. It's the private workflow data your product accumulates every day just by running.
If you're still thinking about AI startup ideas as "a better chatbot for an existing software category," you're already late.
The winning post-SaaS products won't be generic software with AI sprinkled on top. They'll be AI systems wrapped around proprietary workflow data that customers generate every day just by doing their jobs. The moat isn't model quality. It's proximity to the work itself — and the unit economics are concrete. A vertical agent console for freight brokers, construction project managers, or insurance claims adjusters can remove $100,000+ in effective labor cost per seat per year. These aren't vibe-coding side projects. They're real B2B SaaS ideas built on ugly data and expensive human judgment, targeting verticals where operators still spend hours assembling context that AI could retrieve in seconds.

If you've been searching for micro-SaaS ideas in logistics, AI tools for claims automation, or business ideas in construction tech — this is the category worth studying.
Anthropic's February 2026 enterprise plug-in push made the shift visible. The company rolled out workflow-specific plug-ins across finance, HR, engineering, design, and contracts with partners including FactSet, LSEG, Slack, and DocuSign. Software stocks sold off meaningfully in the days that followed. ServiceNow has fallen more than 20% since late January, with analysts partly attributing the decline to concerns about AI-driven competition from Anthropic and others. Hedge funds piled into software shorts. Jefferies noted that Anthropic was no longer just supplying models — it was building complete workflow solutions that compete directly with application-layer companies.
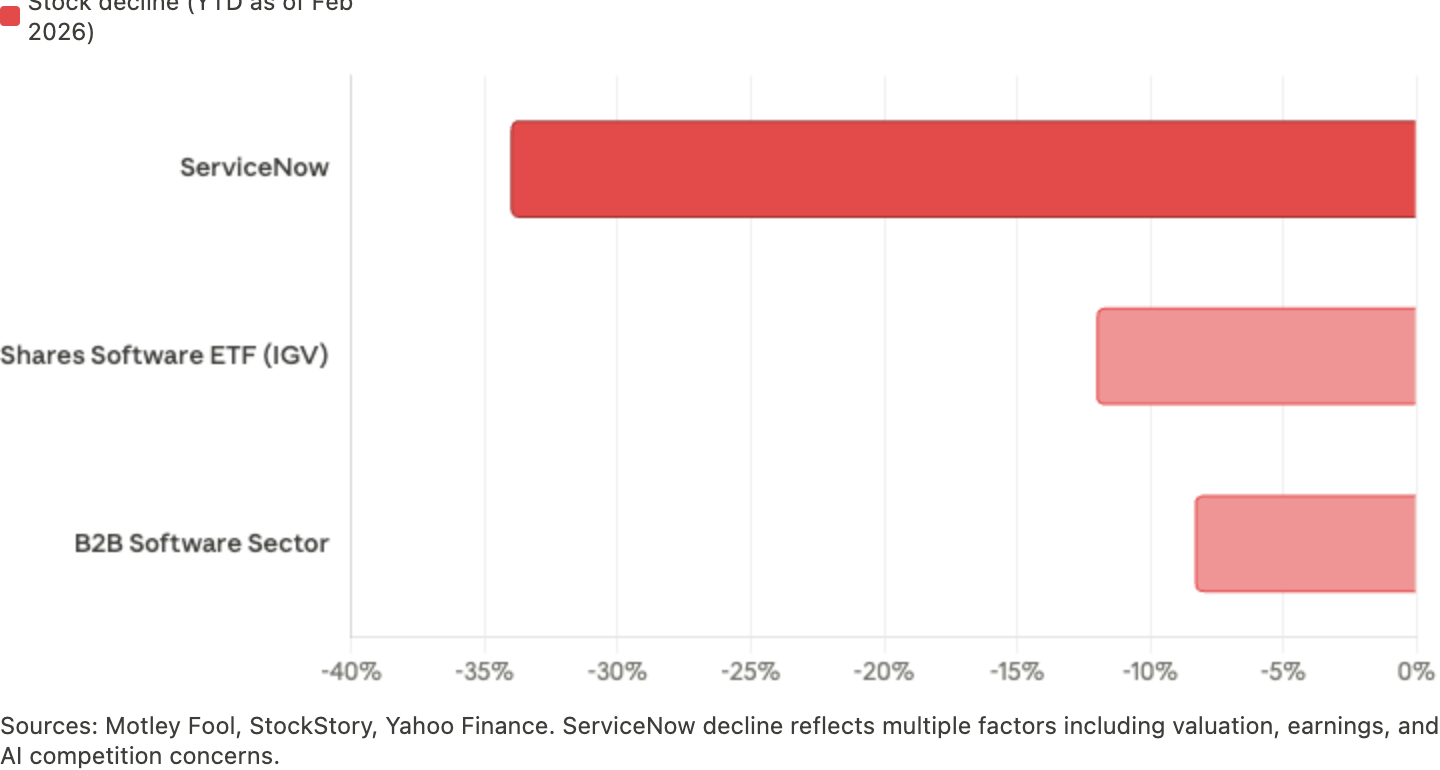
The panic narrative was that AI would kill software. Too shallow. AI is compressing thin software layers and increasing the value of systems that sit closest to source data, operational judgment, and workflow control.
Constellation Research framed the nuance well: Anthropic doesn't own the system of record. It wants to own the reasoning and orchestration layer that sits across systems. Companies with proprietary datasets, domain-specific context, and deeply embedded workflows are more insulated. Thin interface layers and generic horizontal tools are exposed.
VCs are confirming this shift. In a recent TechCrunch survey, enterprise-focused investors reported that startups building thin workflow layers and surface-level analytics are dead money. Abdul Abdirahman at F-Prime said generic vertical software "without proprietary data moats" is no longer attracting interest. Igor Ryabenkiy at AltaIR Capital was blunt: if your differentiation lives mostly in UI and automation, that's no longer enough. The test that matters is simple — if a foundation model provider launches something 10x better tomorrow, does this company still have a reason to exist?
The companies that pass that test are sitting on private, compounding workflow data that foundation models can't replicate.
So stop asking "What market needs another dashboard?" and start asking: Where do people produce high-value data exhaust every day that's still trapped in email threads, PDFs, spreadsheets, transcripts, messages, call notes, change orders, images, approvals, and half-remembered tribal rules?
That's where the next wedge lives.
The best markets are boring, fragmented, and document-heavy
The right markets share a few characteristics. The workflow is repetitive but never fully standardized. The data is messy and mostly private. The outcome matters financially. The incumbent tools were built for record-keeping, not action. The operator still relies on judgment calls and exception handling. And every completed job creates more training data for the next one.

Verticals like construction operations, freight brokerage, insurance claims, franchise operations, niche legal practices, commercial real estate, wholesalers, and agency back offices fit this profile. These industries run on ugly data and expensive human judgment. The software that exists there stores records. It doesn't learn from them.
Three verticals illustrate the pattern.
Construction: $1.3 billion in software revenue, still drowning in document chaos
Procore's 2025 full-year revenue hit $1.323 billion, up 15% year-over-year, with 84% non-GAAP gross margins. Construction software is already a large and sticky category. But construction remains one of the most document-heavy, fragmented, field-driven industries around. Bids, RFIs, submittals, labor allocation, change orders, compliance paperwork — the operational mess persists despite the presence of software.
The play isn't competing with Procore. It's wrapping AI around the specific workflows Procore doesn't automate: the back-and-forth between GCs and subs on change orders, pattern recognition across bid packages, tribal knowledge about which subcontractors consistently miss deadlines on certain project types. That operational memory is where a small team creates a wedge.
Freight brokerage: AI is automating quoting, but the broker survives on exceptions
C.H. Robinson has deployed over 30 generative AI agents automating more than 3 million freight-lifecycle tasks, from pricing to tracking loads in transit. Companies using agentic AI for quoting are compressing turnaround times from hours to minutes and reporting meaningful improvements in win rates.

The broker still survives. Relationships, exceptions, crisis handling — these remain stubbornly hard to automate. The opening isn't about replacing the broker. It's about capturing the broker's operating memory so the agent can handle more routine edge cases every month. The broker stays in the loop, but every accepted quote, every rejected recommendation, every exception resolved trains the next version.
Insurance claims: tens of billions in AI-unlockable value, still manually processed
McKinsey estimates generative AI could unlock $50 billion to $70 billion in insurance industry value. Insurance AI spending is expected to grow more than 25% in 2026. The evidence is already concrete: Aviva rolled out more than 80 AI models across its claims domain, cutting liability assessment time for complex cases by 23 days, improving claims-routing accuracy by 30%, reducing customer complaints by 65%, and saving over £60 million in 2024 alone.
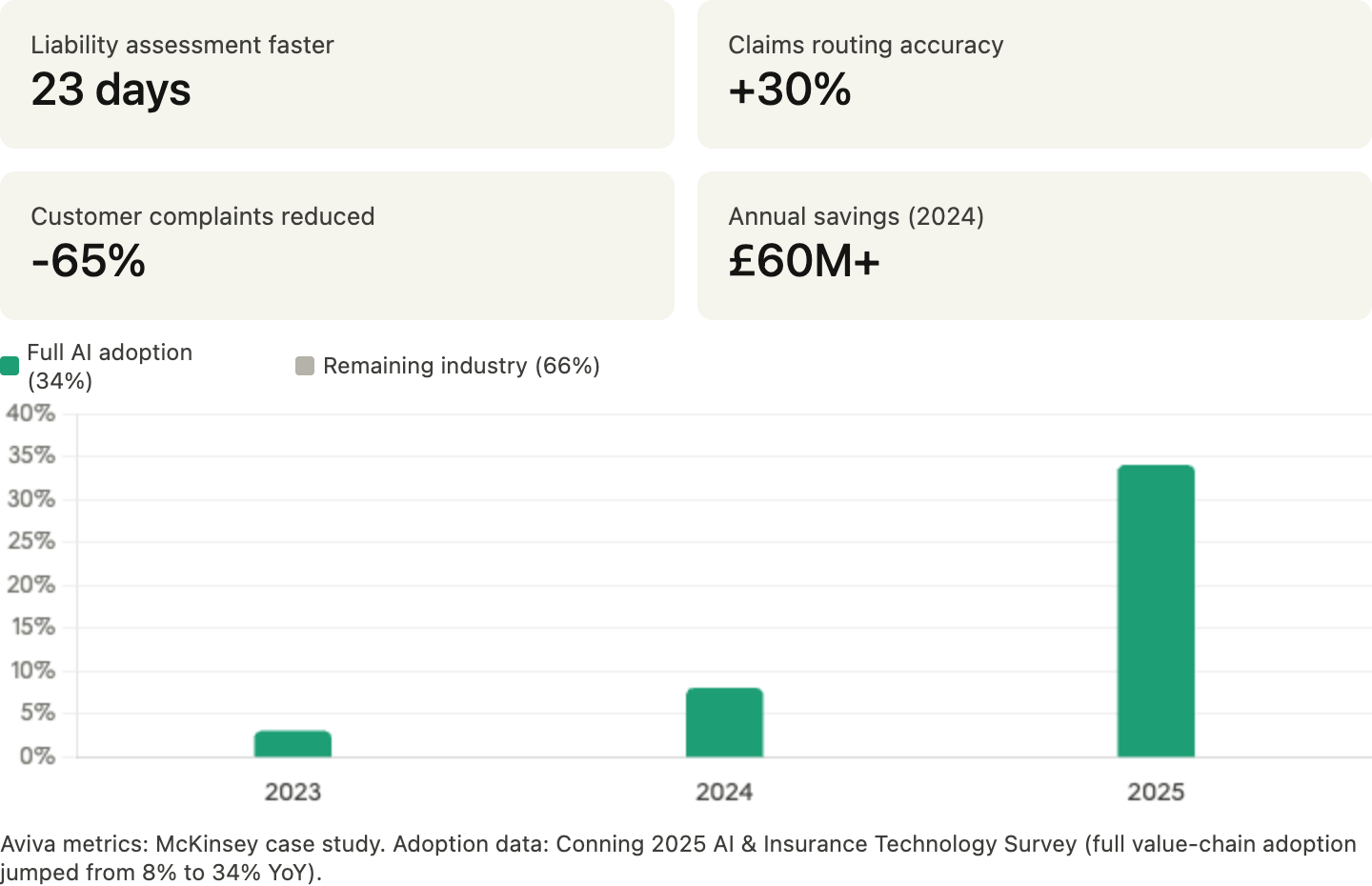
Yet roughly one in three insurers have meaningful AI in production. Average claim cycle times in many property lines now stretch well beyond a month and in some cases are at or near record highs. The gap between what AI can do and what most carriers actually do is enormous. Any niche claims or underwriting workflow with ugly internal data is potentially a startup-sized wedge.
Forget "AI copilot." Think vertical agent console.
Here's the evolution path.
Three phases. Refer to the chart and carefully examine each explanation below. Resist the temptation to skip to phase three.
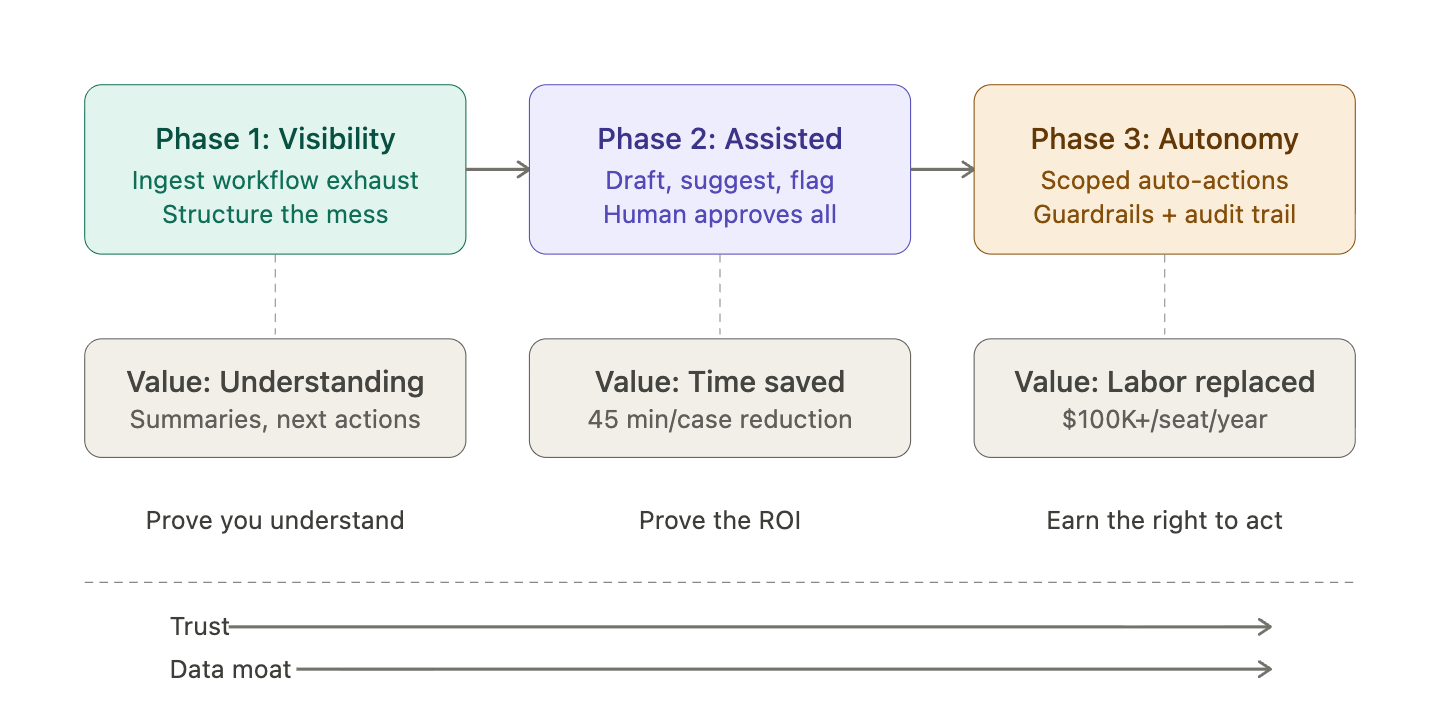
Phase one: Visibility
You start by ingesting operational exhaust from one narrow workflow: emails, attachments, CRM notes, Slack threads, PDFs, spreadsheets, call transcripts, forms, job tickets, historical decisions, approvals, denials, final outcomes.
Then you turn that mess into structured memory. What happened, what usually happens, what should happen next, what's missing, what's risky, what the operator would likely decide.
Phase one means summaries, recommendations, anomaly detection, next-best actions, retrieval over private context. You're not automating anything yet. You're proving your system understands the workflow better than the operator's current tools.
Phase two: Assisted execution
The system drafts replies, prepares documents, suggests quotes, flags missing information, routes approvals, fills forms, assembles work packets. The human still approves everything, but now they're reviewing and editing AI-drafted work instead of starting from scratch.
This is where you prove the ROI. If your system saves 45 minutes per claim, per quote, per bid package — you have a paying customer.
Phase three: Scoped autonomy
The system starts taking low-risk actions automatically inside tightly defined guardrails: sending follow-ups, requesting documents, routing tasks, generating standardized outputs, escalating edge cases, learning from acceptance or override patterns.
You earn the right to automate. You don't begin by promising a fully autonomous employee. In plenty of verticals, customers will accept AI assistance faster than AI autonomy. Trust drives adoption, and audit trails matter enormously in regulated industries.
The blueprint: a vertical agent console for one expensive workflow. A narrow console that becomes the memory layer, then the recommendation layer, then the action layer for a specific kind of work.
Where the real moat comes from
Founders say "data moat" too casually. The moat here isn't just having data. It's having interaction-linked outcome data inside a live workflow.
That means knowing which inputs led to which outputs. Which recommendations were accepted or rejected. Which exceptions occurred and how they were resolved. Which customers or vendors behaved differently. Which missing fields caused delays. Which phrasing improved response rates. Which quote structures won and which lost. Which claims patterns led to denial or approval. Which project circumstances correlated with change orders or overruns.
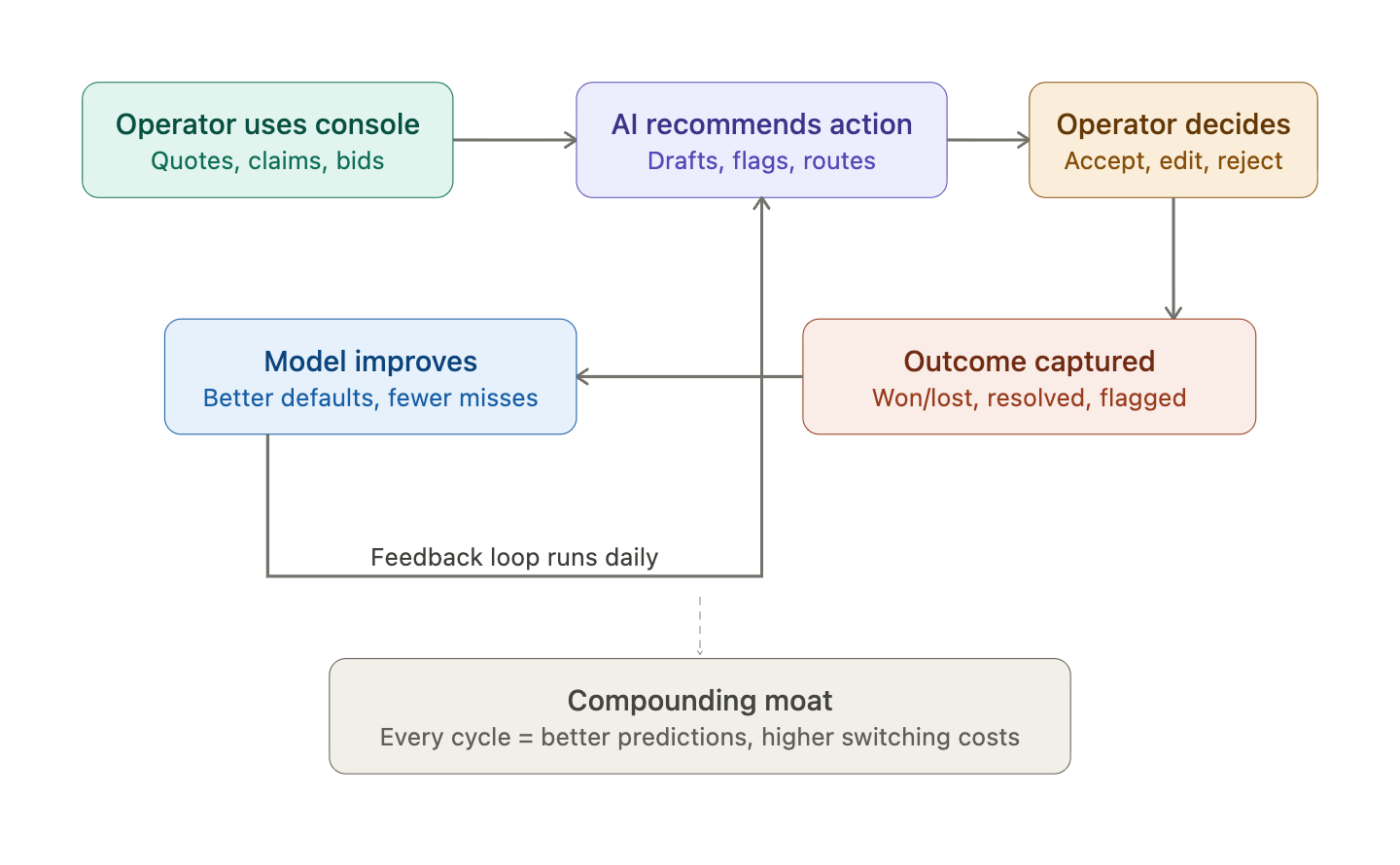
This isn't static proprietary content. It's compounding operational memory.
Foundation models will keep commoditizing. The scarce asset isn't raw intelligence — it's exposure to repeated, high-value decisions in context. And data quality matters more than data quantity. If competitors can source similar data or reverse-engineer model outputs, the perceived moat evaporates. The moat holds only when your data comes from live workflow participation, not scraping or aggregation.
This is also why incumbents aren't invincible. Yes, the best-positioned ones own data. But many use that advantage poorly because their products were designed to store records, not to become adaptive workflow brains. The startup advantage is speed. You can choose one painful lane, instrument the workflow aggressively, and turn data exhaust into action faster than a broad incumbent can reorganize its product architecture.
Both a heist play and a long-term platform play
The opportunity works on two time horizons at once:

Unlock the Vault.
Join founders who spot opportunities ahead of the crowd. Actionable insights. Zero fluff.
“Intelligent, bold, minus the pretense.”
“Like discovering the cheat codes of the startup world.”
“SH is off-Broadway for founders — weird, sharp, and ahead of the curve.”





