















Start as a fixed-fee evaluation shop. Compound every engagement into a proprietary test library. Evolve into an EvalOps platform and, eventually, a certification layer that becomes part of how companies buy and ship AI.
A solo founder or two-person team can hit $300K–$650K in annualized gross profit on two engagements per month — before retainers start compounding.
Frontier AI labs are hiring people with expertise in chemical weapons, biological risk, explosives, and radiological threats — to test whether their own models could become dangerous instruction engines. Anthropic has advertised for a policy manager focused on chemical weapons and high-yield explosives, including knowledge of radiological dispersal devices. OpenAI has formalized a Preparedness framework evaluating frontier-model risk across CBRN, cyber, persuasion, and autonomy, with evals covering subtopics as specific as radiological exposure and sabotage of nuclear infrastructure. This is now part of the release machinery for top models.

The commercial opportunity is much bigger than "dirty bomb experts for AI labs."
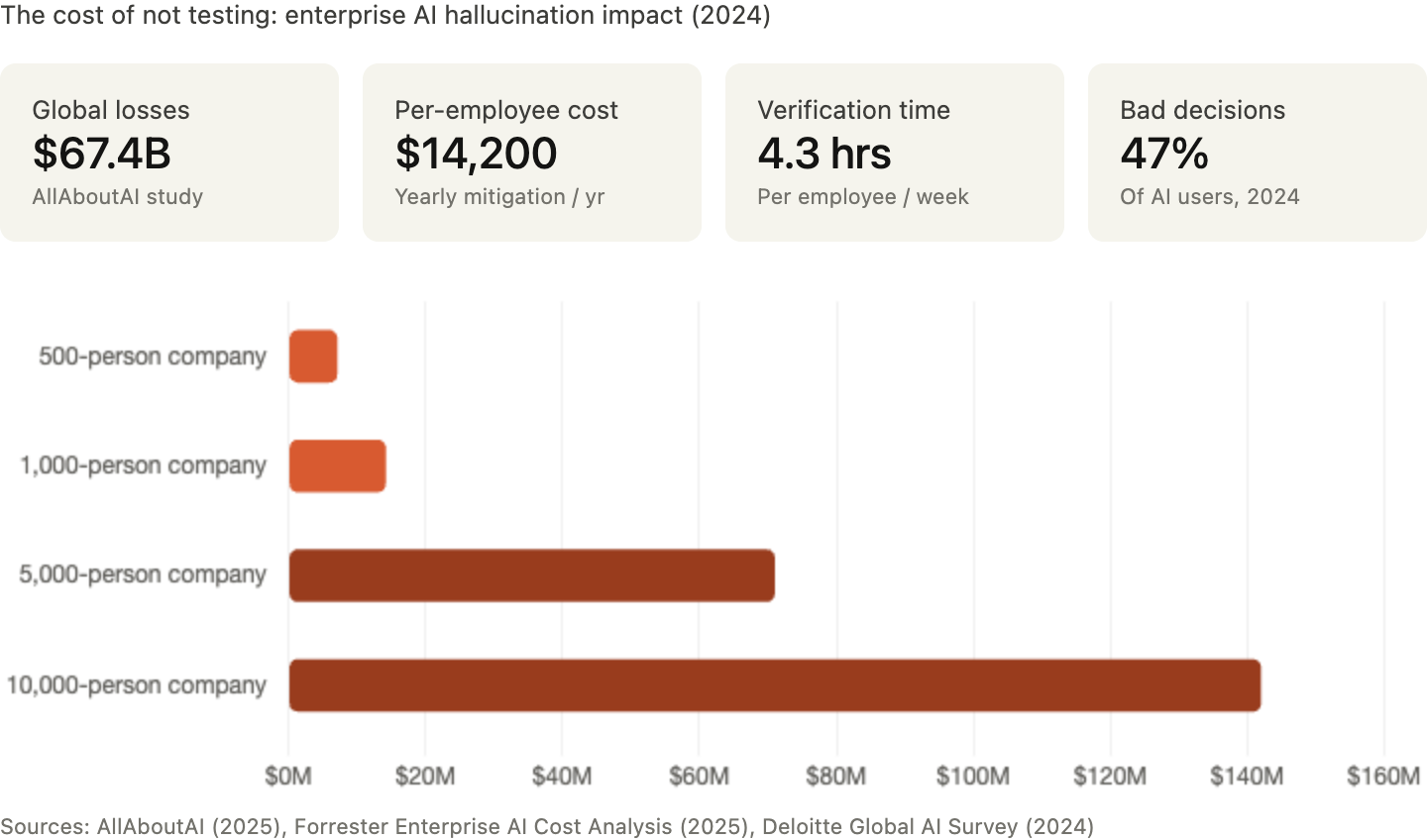
Every company shipping AI into a consequential workflow — contract review tools, insurance copilots, HR assistants, finance operations software — will need someone to prove the system does not fail in the dumbest, most expensive, most lawsuit-worthy ways possible. Global financial losses tied to AI hallucinations reached an estimated $67.4 billion in 2024. Knowledge workers are burning 4+ hours per week just verifying AI outputs. Courts are sanctioning lawyers who submit fabricated AI citations. And the EU AI Act's adversarial testing requirements for high-risk systems become enforceable on August 2, 2026 — pulling thousands of enterprises into structured AI evaluation whether they want it or not.
This is one of the more executable AI startup ideas available right now — a B2B service business that requires no proprietary model, no research lab, and no venture funding to reach meaningful revenue.
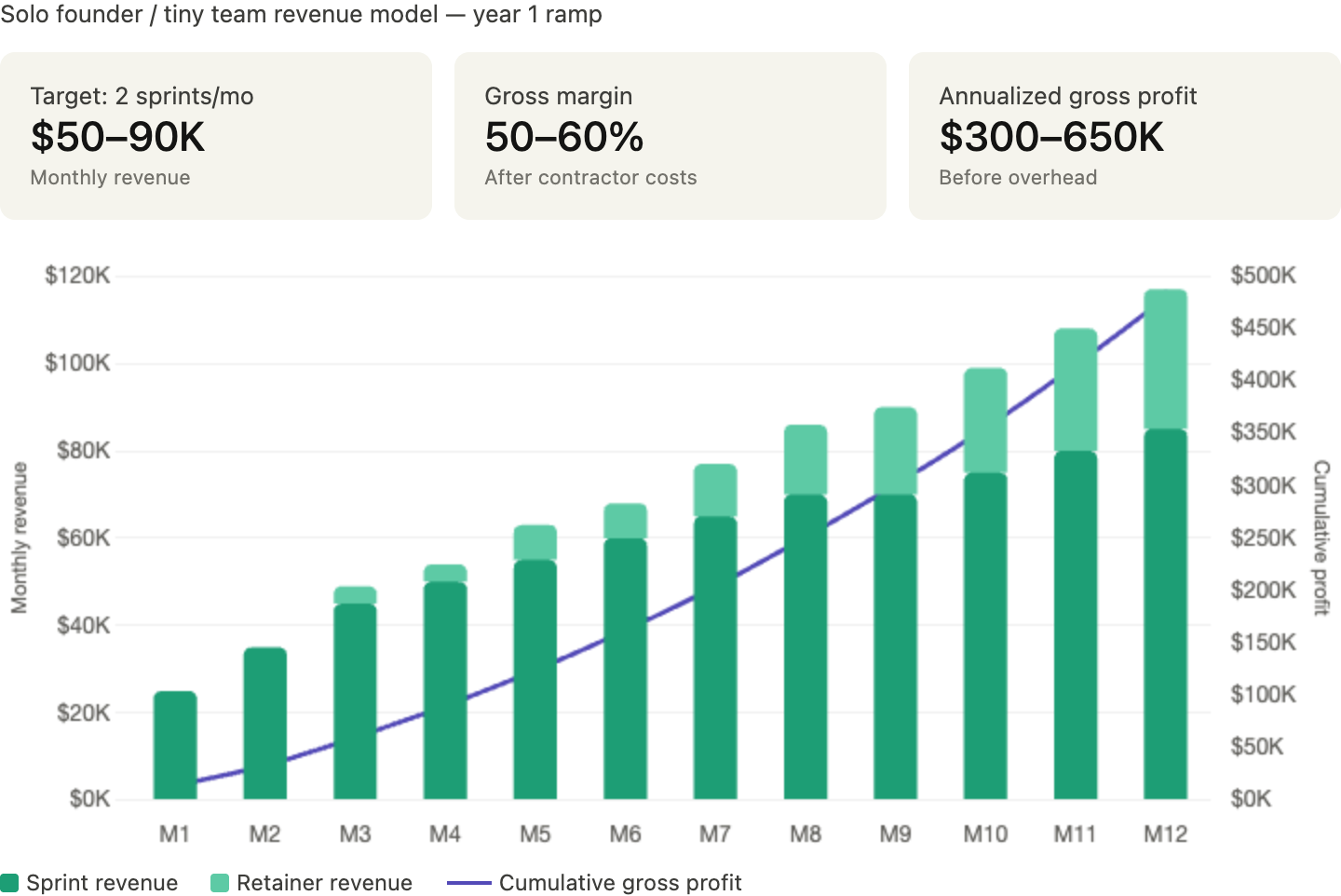
Frontier labs are paying to contain catastrophic risk. The rest of the market will pay to contain ordinary but costly risk. The startup opportunity lives squarely in that second camp.
The cleanest framing isn't "AI safety startup." Too broad, already crowded. Think instead: vertical red teaming for AI applications — a productized service built around domain experts who know how specific AI tools can quietly go wrong in production.
You are not building the model. You are building the company that hires, organizes, and operationalizes domain experts to break AI systems before customers or opposing counsel do. It starts as a services business. But build it correctly, and the service is only the collection layer for something far more valuable: proprietary evaluation data, repeatable testing frameworks, and eventually a certification layer that becomes part of enterprise procurement.
Why This Market Is Real Now
The AI red teaming services market hit roughly $1.1–1.4 billion in 2024–2025, with analysts projecting mid-20s to low-30s CAGR through the end of the decade. Multiple market reports converge on this range, and the growth is coming from every direction at once.
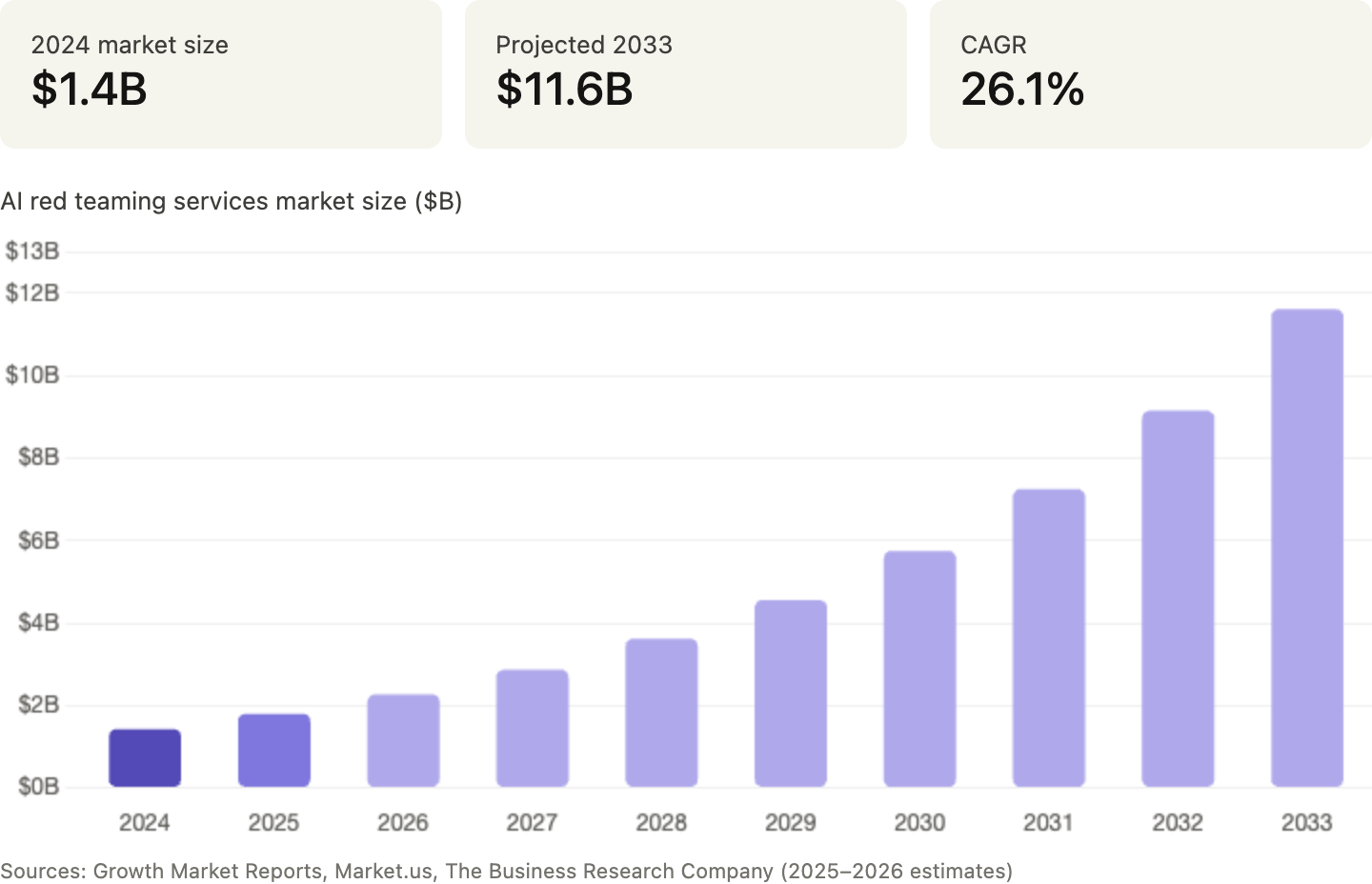
Start with behavior. Anthropic's Responsible Scaling Policy makes evaluation and risk thresholds central to deployment decisions. OpenAI's Preparedness framework ties catastrophic-risk mitigations to deployment gates. When the most advanced labs in the world build release processes around evals, the rest of the market copies the pattern — and needs help doing it.
Then look at vendor formation. CrowdStrike launched AI Red Team Services in late 2024. Pentera acquired EVA Information Security, an offensive security firm specializing in AI red teaming, specifically to extend its validation capabilities into AI environments. OWASP formalized a 2025 Top 10 for LLM applications. NIST's Generative AI Profile gives organizations a shared language for measuring generative AI risk. Categories become businesses when buyers get both fear and vocabulary. Both have arrived.

The cost of not testing is where the numbers get ugly. Industry reports peg enterprise hallucination-related costs at roughly $14,200 per employee per year in mitigation efforts. Nearly half of enterprise AI users made at least one major business decision based on hallucinated content in 2024. In legal services, courts dealt with hundreds of rulings addressing fabricated AI citations during 2025, and judges are now sanctioning attorneys who submit them. UK courts have signaled that failure to verify AI outputs may itself constitute professional misconduct.
Forced demand is arriving on a deadline. The EU AI Act requires adversarial testing for high-risk AI systems before market deployment, with key obligations enforceable from August 2, 2026. Penalties reach €35 million or 7% of global annual turnover. The Act has extraterritorial reach — companies outside the EU must comply if their AI systems affect EU citizens. In the US, California and New York passed new laws regulating frontier AI models in late 2025. The SEC flagged AI-driven threats as an examination priority. And a coalition of 42 state attorneys general is signaling coordinated enforcement throughout 2026.
There is also an emerging insurance angle. Cyber insurance carriers are beginning to introduce AI-specific riders and conditions tied to documented adversarial testing, model-level risk assessments, and alignment with recognized frameworks. Some Lloyd's brokers have added hallucination-related exclusions. Carriers are experimenting with premium credits for documented RAG workflows and human review checkpoints. This is still an evolving practice — not yet an industry standard — but the trajectory is clear: organizations without demonstrable AI security practices will face coverage limitations or higher premiums.
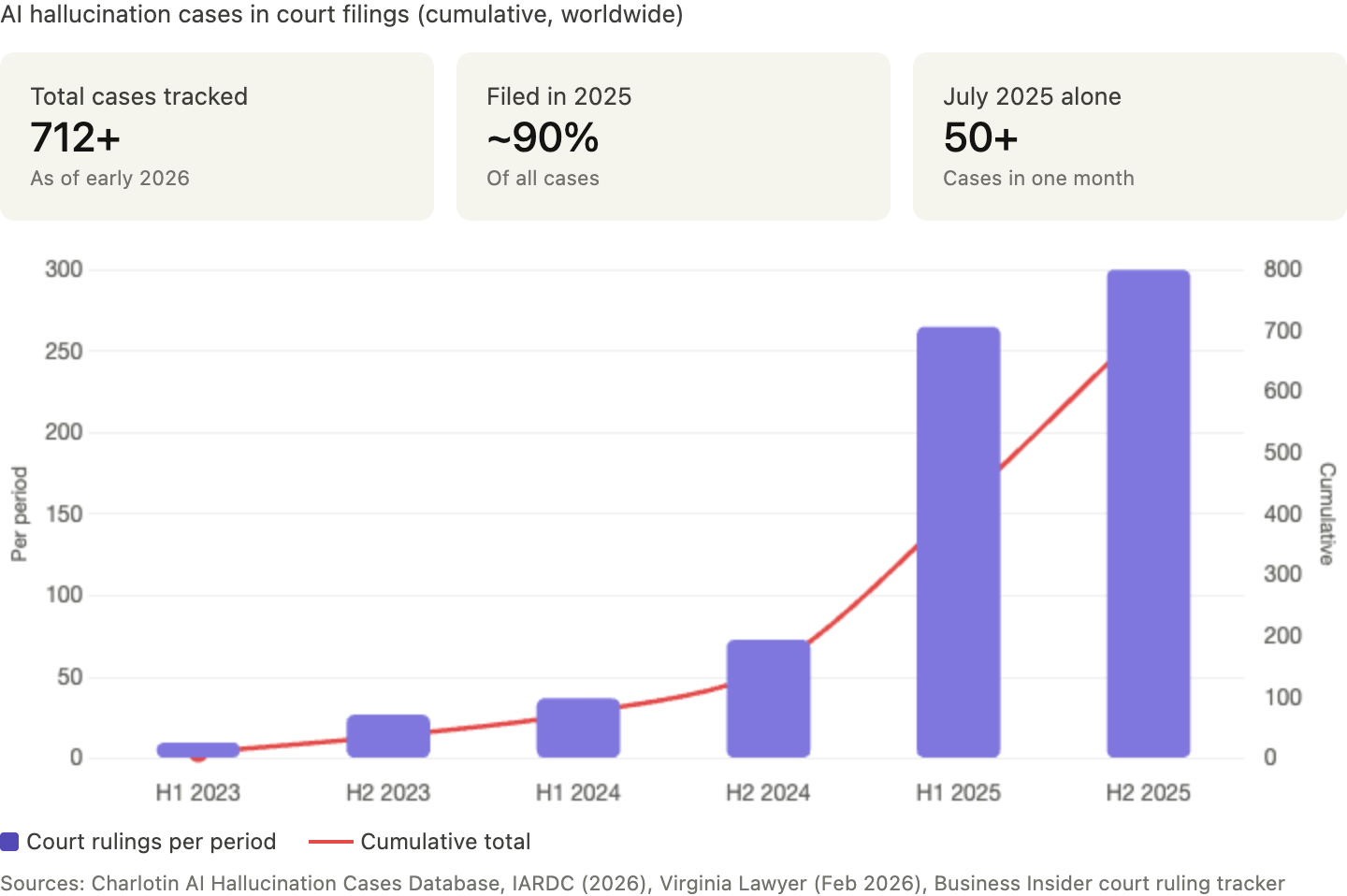
Regulation, litigation, and insurance are all converging on the same purchasing decision: independent verification that AI works safely enough to ship.
Where the Market Is Still Open
Security firms already test AI systems. Most come from the cybersecurity side — strong on prompt injection, insecure output handling, data leakage, supply-chain issues, and deployment vulnerabilities. Those are real problems. They are not the entire problem.
The market is still wide open at the application layer, where the core question shifts from "can this model be jailbroken?" to "can this product do costly damage in its actual job?"
Generic AI testing falls short for high-consequence use cases. Anthropic's published work on red teaming makes clear that real failures are often context-dependent — meaningful evaluation requires specialized expertise and structured attack methods. The lesson extends well beyond national security: the closer AI gets to real work, the more failure becomes domain-specific. A generalist security tester can find prompt injection. A veteran labor lawyer can find the clause that gets a company sued. A practicing pharmacist can catch the drug combination that could hurt someone.

OWASP and NIST help define the baseline. They do not provide the domain-specific attack inventory that a claims assistant, contract tool, or healthcare copilot actually needs.
This is a new labor market wrapped in software. You are converting underused expertise into structured evaluation work. The scarce input isn't red-team talent — it's domain judgment. AI companies can already hire security engineers, prompt specialists, and policy generalists. What they cannot easily hire on demand is a bench of people who know the exact ways a contract assistant, a medical workflow, an underwriting model, or a payroll copilot can quietly go wrong in the real world.
Incumbent security vendors will eventually drift into application-layer evals if the playbook becomes obvious. The window is open now because most of them are still tooled for infrastructure-level testing, not workflow-level domain expertise. Speed matters.
The Real Heist: Service, Moat, or Both?
This business works as both a fast heist and a long-term moat, depending on how disciplined you are about building it.
As a fast heist, it's strong. You can start with no deep proprietary tech. You only need a narrow wedge, a credible process, a clean deliverable, and a handful of high-signal contractors. Companies are already anxious about shipping AI features into sensitive workflows, and many lack internal talent to test them properly. This is a founder-led sales business, not a research lab. A solo operator or tiny team can get to revenue quickly.
As a long-term moat, it's stronger than it looks. The moat isn't the contractor list by itself — contractors can churn. The moat is the eval corpus: the prompts, scenarios, failure types, annotations, severity labels, remediation mappings, and cross-model comparisons you collect over time. Once you have enough of that data in one vertical, you can start turning human-crafted tests into semi-automated evaluation suites. Eventually, clients aren't just paying for access to experts. They're paying for a living benchmark that gets smarter every month and becomes part of their release process.
Anthropic has already said its goal is more frequent testing with automated evaluation, elicitation, analysis, and reporting. The application layer will move the same direction, and whoever builds the benchmark data first owns that transition.
The obvious version starts as an agency. A B2B SaaS company ships an AI feature. You bring in a handpicked group of domain experts to attack it. They try edge cases, adversarial prompts, ambiguous scenarios, policy evasions, workflow abuses, and customer-like misuse. You produce a risk report, prioritized fixes, and a clean before-and-after narrative the client can use internally and in sales.
The larger play is to become the system of record for vertical AI evaluations. That means building three compounding assets:
- A vetted network of domain specialists — ex-lawyers, clinicians, claims operators, underwriters, compliance managers — trained on structured adversarial testing methods.
- A growing library of adversarial test cases organized by vertical and use case, covering the scenarios, failure types, severity labels, remediation mappings, and cross-model comparisons you collect engagement after engagement.
- A scoring and reporting engine that lets clients rerun those tests every time they change prompts, models, policies, or retrieval pipelines.
Own those three things and you stop being a consultancy. You start becoming infrastructure.
Then there's the badge. Enterprise buyers love external proof when buying new risk. If you can create a recognizable standard — even a modest one — around "evaluated AI workflows," you stop selling consulting hours and start selling procurement comfort. "Evaluated by independent domain experts" shortens security reviews, helps internal champions defend adoption, and increases close rates. In enterprise software, trust artifacts often become product features.
One important caveat: the EU AI Act does not anoint private certifiers. Your "standard" has to become de facto through network effects with vendors and buyers, not through regulatory mandate. That means the badge only works if enough companies in your vertical adopt it that procurement teams start expecting it.
The natural evolution: agency → software-assisted service → EvalOps platform → certification layer.
At the platform stage, customers log in, connect model endpoints or sandbox environments, choose scenario packs, assign human reviewers, run evaluations, and export evidence. At the certification stage, you become the trust layer between AI vendors and buyers.
The Best Wedge for a Small Team
Do not start with healthcare. The risk is obvious, but the sales cycles are slow, the regulatory surface is enormous, and the edge cases can crush a young company. Do not start with frontier-model labs either — they build internally.
Start with mid-market B2B SaaS companies shipping AI into workflows where mistakes are expensive but compliance is manageable. Good early wedges:

Unlock the Vault.
Join founders who spot opportunities ahead of the crowd. Actionable insights. Zero fluff.
“Intelligent, bold, minus the pretense.”
“Like discovering the cheat codes of the startup world.”
“SH is off-Broadway for founders — weird, sharp, and ahead of the curve.”





