















Build a vertical AI verification tool — a "verify() layer" — that sits between raw LLM output and real business decisions. Instead of asking one model for one answer, your product queries multiple models, scores agreement, localizes disagreement, and writes an audit trail.
This is not a chatbot or a model comparison playground. It is workflow-embedded B2B SaaS for teams in procurement, sales intelligence, or compliance who already use AI but cannot afford to trust it blindly.
A 10-model consensus query now costs roughly $0.08. Vertical versions of this product price at $499–$6,000/month per team, with enterprise contracts above $12,000/year. For a small team building a focused AI startup around one painful workflow, the path to $20K–$100K MRR is concrete and fast.
Most founders looking at AI are still asking the wrong question. They ask which model will win. The better question: which layer becomes indispensable once nobody fully trusts any single model?
A new class of micro SaaS ideas is forming around a single bet: instead of asking one model for one answer, call several, compare their outputs, surface where they agree and diverge, and present something closer to a defensible conclusion than a raw chatbot response. CollectivIQ is an early, explicit version of this thesis. It launched in March 2026 as an AI consensus platform that queries ChatGPT, Claude, Gemini, Grok, and up to ten other LLMs in parallel, then highlights agreement and disagreement to reduce hallucinations, bias, and vendor lock-in.
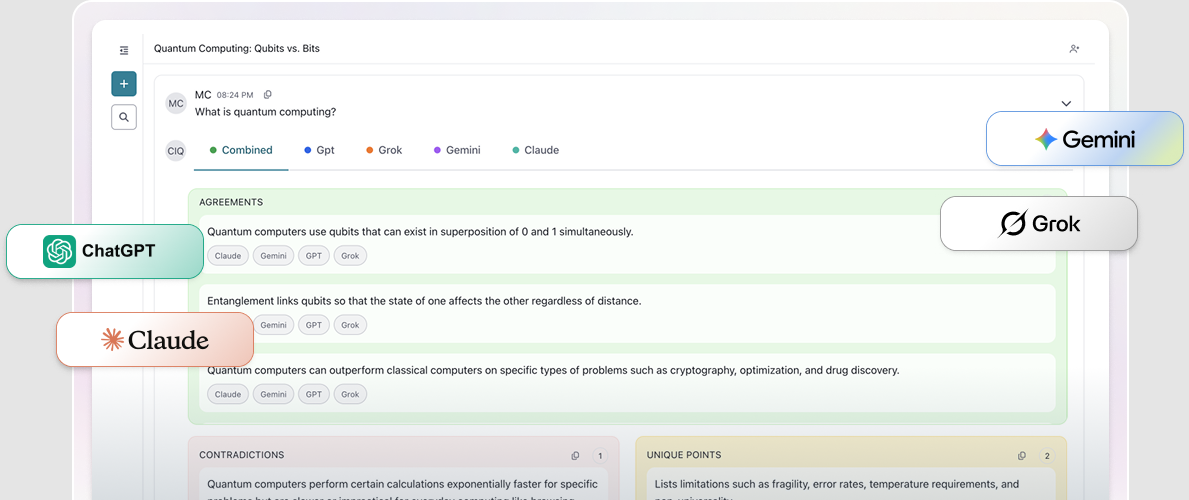
The origin story matters: CollectivIQ was born inside Buyers Edge Platform, a multi-billion-dollar digital procurement company. As generative AI usage spread among its 1,250 employees, leadership kept running into the same problems — inaccurate answers, expensive per-seat subscriptions, data governance gaps, and siloed conversations that erased institutional knowledge. Rather than pick one vendor, they built a consensus engine across all of them.
The product itself is interesting. The market signal beneath it is more interesting. Enterprise AI is moving out of demo mode and into workflows where wrong answers are expensive. The verification gap — the space between what models generate and what teams can safely act on — is widening fast. And the tools filling that gap look less like chatbots and more like B2B SaaS infrastructure for decision verification and AI-assisted risk reduction.
Why This Matters Now
AI hallucinations cost enterprises an estimated $67.4 billion globally in 2024. Each enterprise employee costs roughly $14,200 per year in hallucination-related mitigation, per Forrester. Knowledge workers spend an average of 4.3 hours per week just verifying AI outputs. A Deloitte survey found that 47% of enterprise AI users made at least one major business decision based on hallucinated content in 2024.
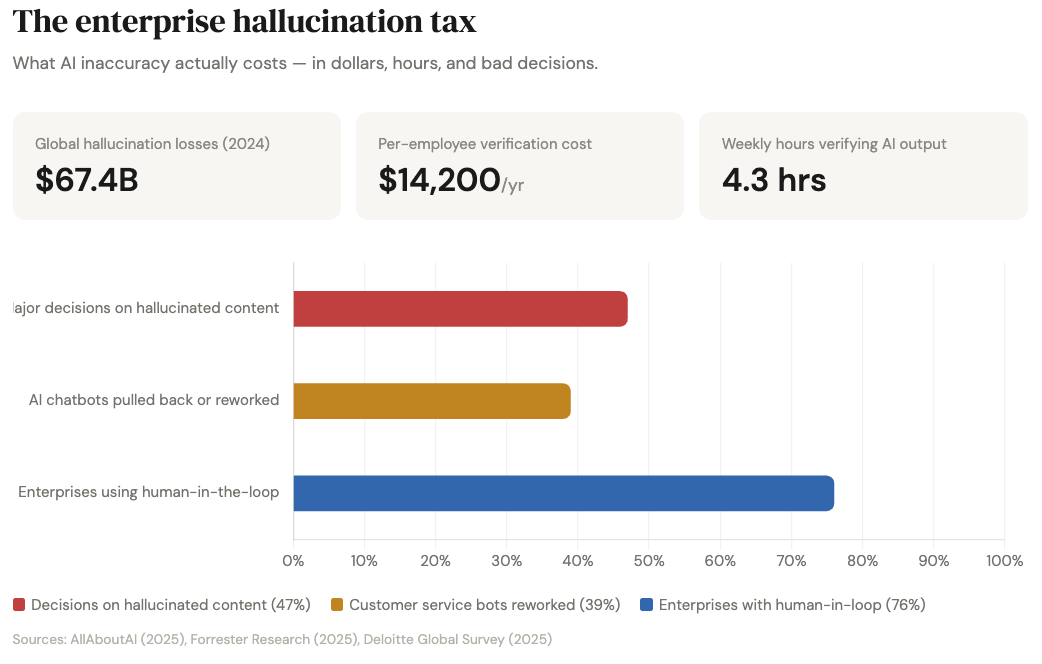
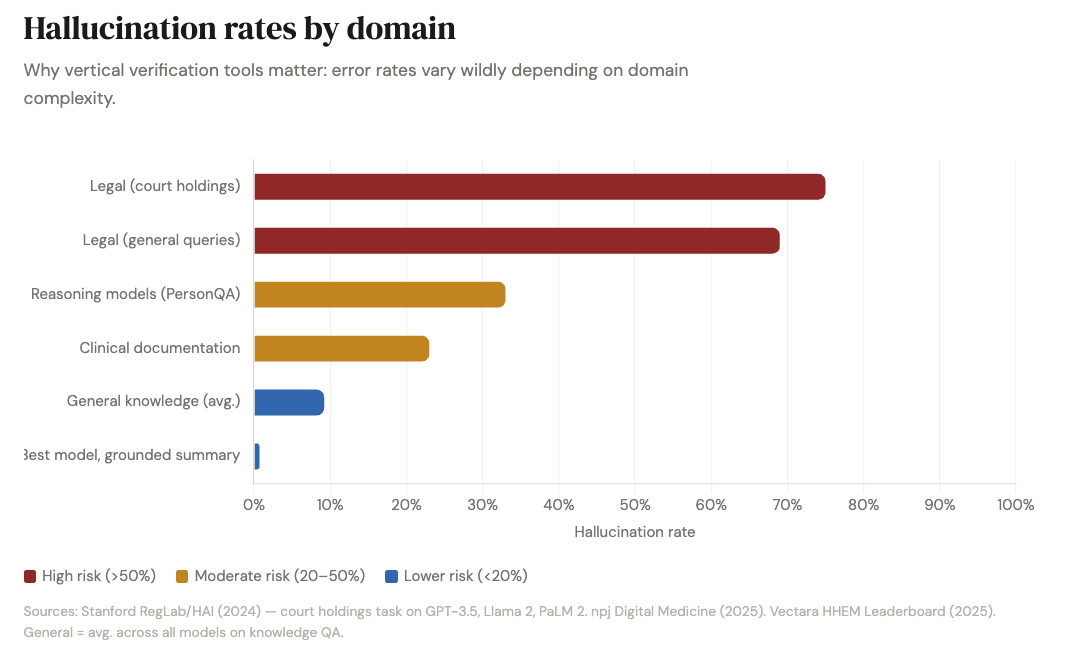
The problem compounds in specialized domains. Stanford researchers found LLMs hallucinate at least 75% of the time on specific legal queries, and clinical hallucination rates hit 23% even with the best safeguards. Financial services firms report individual AI-error incident costs ranging from $50,000 to $2.1 million. MIT researchers found in January 2025 that AI models use 34% more confident language when hallucinating than when stating facts. The wronger the AI is, the more certain it sounds.
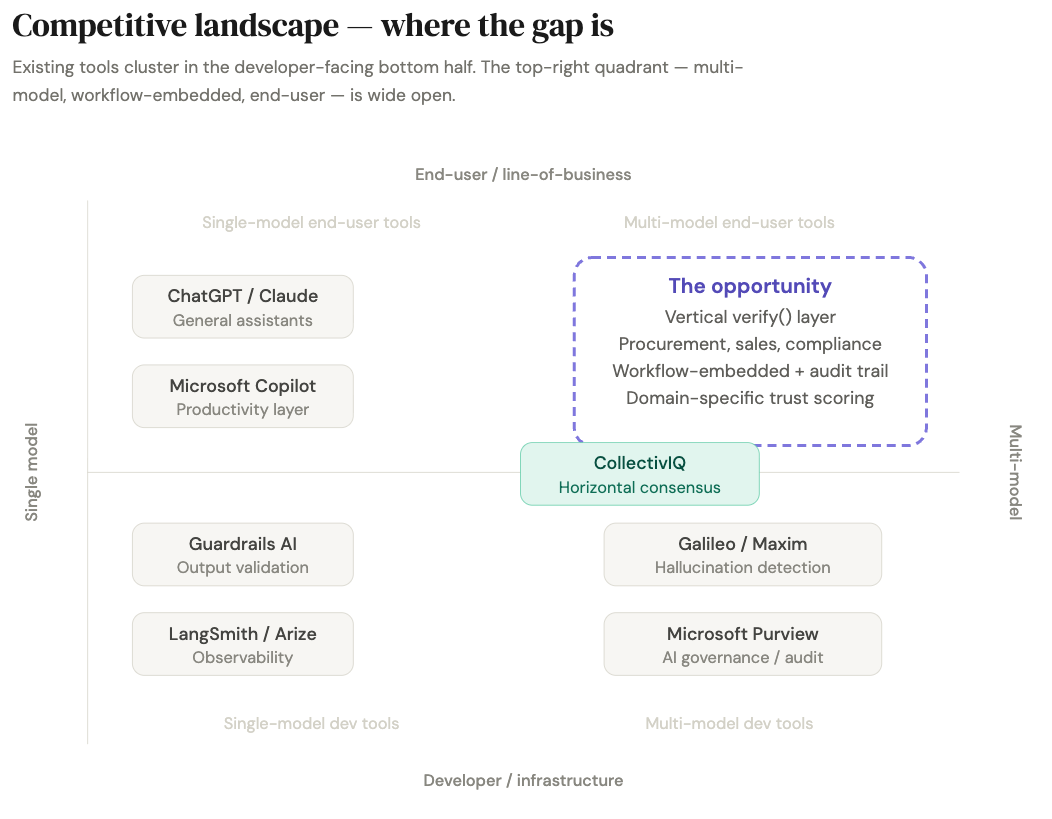
The hallucination detection tools market grew 318% between 2023 and 2025. Specialized evaluation platforms — Galileo, Maxim, LangSmith, Arize — are carving out a distinct purchasing category around monitoring, evaluation, and blocking risky outputs in production. But these tools skew heavily toward developer and infrastructure personas. They are dashboards and SDKs, not workflow products for the procurement lead, compliance manager, or sales enablement head who actually needs a verified answer before acting on it. That gap is the opening.
The research backing multi-model approaches is stronger than most people realize. A 2024 ICML Best Paper showed that structured cross-model disagreement significantly improves factual accuracy and reasoning — even when all participating models initially generate incorrect answers, the debate process frequently converges on the correct one. Ensemble approaches have demonstrated 7–45% accuracy improvements over single-model baselines depending on task type. A 2025 clinical study found that human-AI collectives outperformed single physicians, physician groups, individual LLMs, and LLM ensembles in diagnosis tasks. Combining models — or combining humans and models — consistently beats trusting one answer from one black box.
Then there is the regulatory accelerant. The EU AI Act's high-risk obligations take full effect on August 2, 2026, less than five months away. High-risk AI systems must produce traceable audit logs and human-readable justification for automated decisions. Penalties reach up to €35 million or 7% of global annual turnover. Gartner forecasts AI governance platform spending will reach $492 million in 2026 and cross $1 billion by 2030. Only one in five companies currently has a mature governance model for autonomous AI agents. The Act's requirements around logging, traceability, and human oversight map almost perfectly onto a verification-and-audit product. "We verify AI outputs and keep an immutable ledger" is no longer a nice-to-have pitch — it tracks directly to regulatory language for high-risk systems.
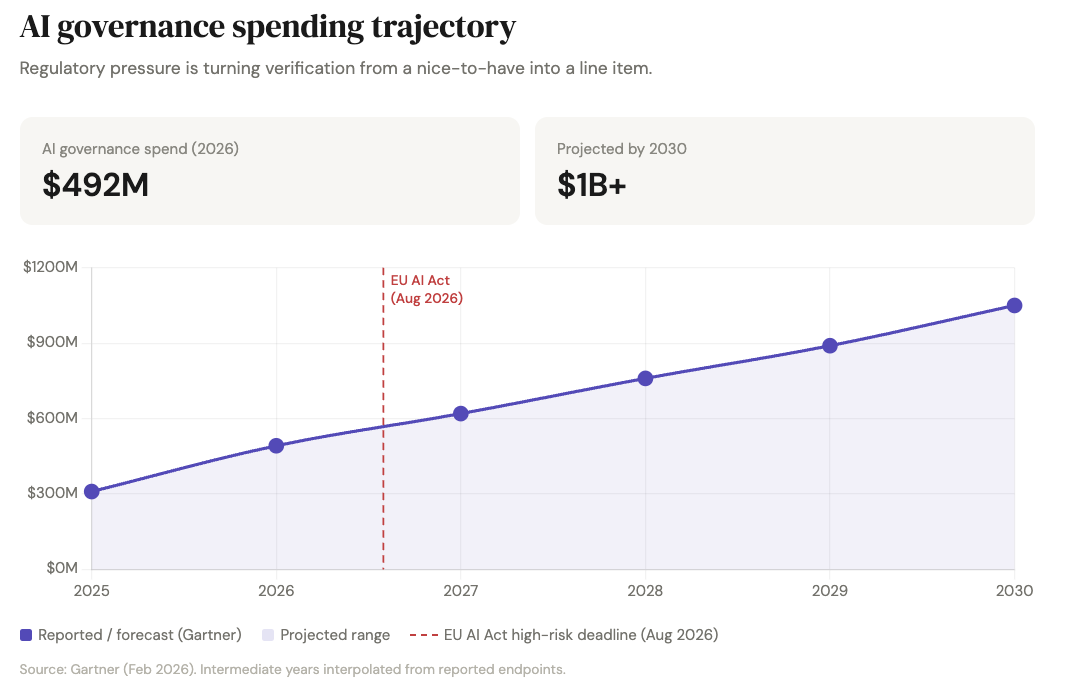
All of this means "we verify AI outputs before they reach a decision-maker" is an increasingly easy sell.
The Premise
If you are building for consumers, side-by-side model comparison is a neat feature. If you are building for enterprises, it can become the answer-verification layer that sits between raw model output and a real decision. That distinction is everything.
"Ask ten bots" is not the business. The market is beginning to accept a deeper idea: confidence can be productized. The winning product converts messy model disagreement into a usable decision primitive. How confident should this answer be? Where exactly is the disagreement? What evidence supports the final output? What should a human review before this goes live? Can the company prove later how the answer was generated?
You are not competing with OpenAI, Anthropic, Google, or xAI on raw intelligence. You are selling something they are structurally awkward at selling: a neutral trust layer above all of them. Single-model vendors can add internal confidence scores, but those scores are self-referential. They don't solve vendor concentration risk or create cross-vendor auditability. They don't tell you when another frontier model strongly disagrees. And they don't create a neutral record that a compliance team or internal auditor can use later. Microsoft Purview is already positioning itself as governance infrastructure for AI usage and auditability, but governance tools mostly track usage, data controls, and audit logs. They are not yet the default layer for adjudicating whether a model-generated answer itself should be trusted.
The founder mistake would be to ship a dashboard that says "here are five model answers." The smarter move is to ship a workflow product that says: "Here is the answer. Here is the confidence band. Here are the disputed claims. Here is the evidence trail. Here is the approval record." That is how a feature becomes infrastructure.
The Insight: Sell the Disagreement
Most AI products try to hide uncertainty because uncertainty feels like weakness. In enterprise workflows, the opposite is true. Uncertainty is the product.
If 92% of a memo or recommendation is boring and uncontested, and 8% is where the models diverge, your tool has saved the user real time and focused their judgment exactly where it matters. Internal audit teams, legal ops, compliance leaders, and procurement teams are not paying for "AI magic." They are paying to narrow the review surface and preserve evidence.
Bloomberg's newest AI tooling is valuable precisely because it turns large volumes of information into structured, comparative, attributable research inside a workflow professionals already trust. You are not building a chatbot people interact with for fun. You are building the terminal where people verify AI-assisted judgment.
Disagreement localization — not consensus — is the real category-defining angle.
Where the Actual Play Is
The Fast Heist
Build a narrow, vertical consensus copilot in a workflow where people already use AI but don't fully trust it:

Unlock the Vault.
Join founders who spot opportunities ahead of the crowd. Actionable insights. Zero fluff.
“Intelligent, bold, minus the pretense.”
“Like discovering the cheat codes of the startup world.”
“SH is off-Broadway for founders — weird, sharp, and ahead of the curve.”





