




















Most founders look at FDA Complete Response Letters and see biotech paperwork. You should see a new market — and one of the more unusual B2B data startup ideas to emerge this year.
In July 2025, the FDA published more than 200 Complete Response Letters on its openFDA platform — the formal documents explaining why a drug application was rejected. In September, the agency dropped a second batch of 89 previously unpublished letters and committed to prompt, ongoing disclosure of future CRLs. The database now includes letters issued as recently as 2025 and functions as a live transparency feed.
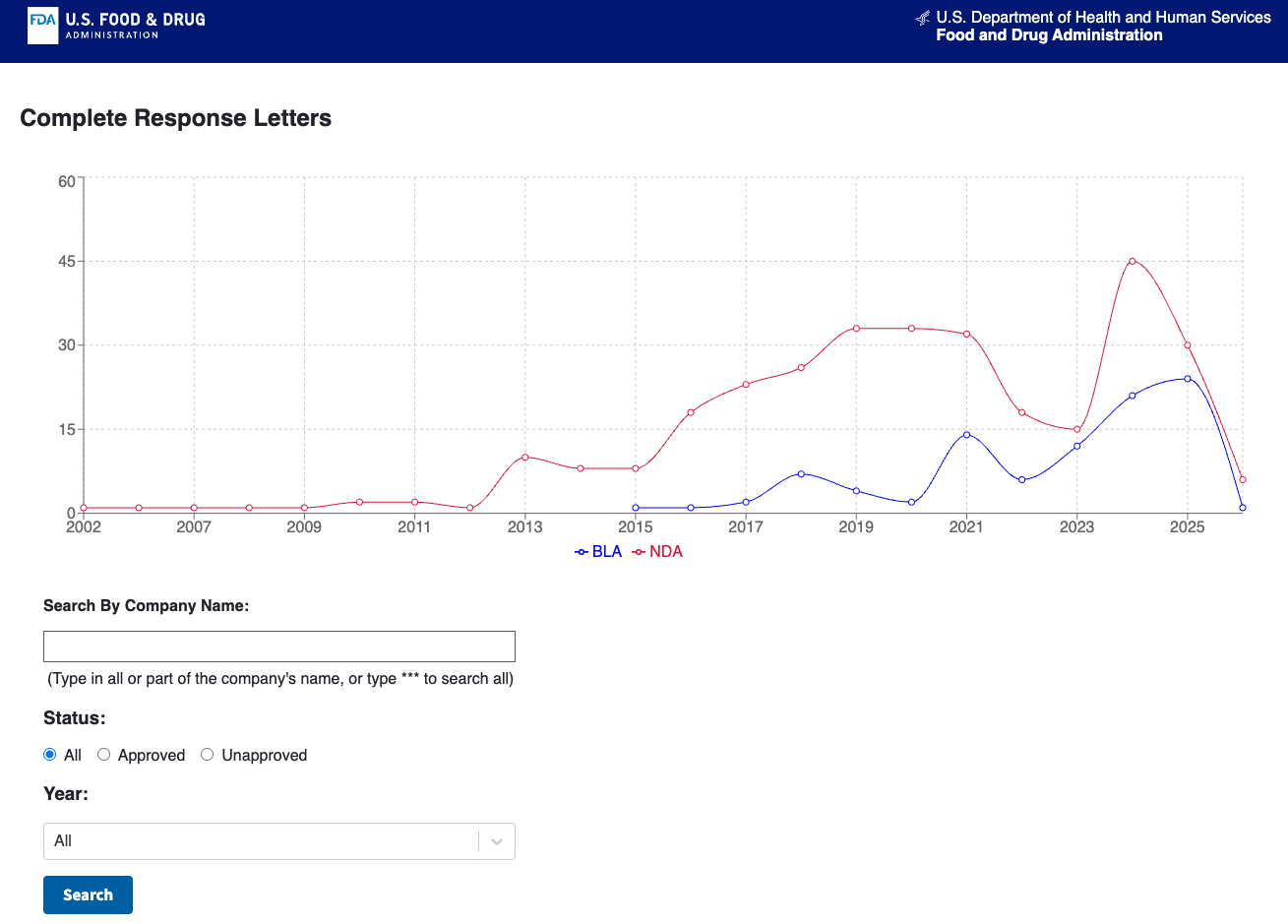
Prior to this year, CRLs were almost never seen beyond the sponsor. Now they're public, machine-readable, and accumulating. Each letter is a structured explanation of why an application stalled: manufacturing deficiencies, safety findings, clinical design flaws, statistical shortcomings, labeling gaps, assay weaknesses, facility readiness failures. A detailed autopsy of a drug program that hit a wall — available to anyone who knows what to do with it.
Niche intelligence products in regulated industries command premium pricing. The right build here supports $12,000–$25,000 annual subscriptions per firm, $5,000–$20,000 custom diligence engagements, and eventually six-figure embedded data feeds — all from a free public dataset that nobody has structured yet.
If you're hunting for healthcare startup ideas or regulatory data business opportunities that a small team can own, this is a strong candidate.
Why This Data Matters Now
Drug development costs somewhere between $708 million (per a January 2025 JAMA Network Open analysis of 38 drugs) and $2.23 billion (per Deloitte's 2024 top-20 pharma analysis). Phase III trials completed in 2024 averaged $36.58 million each, up 30% from 2018. The average likelihood of approval for a drug entering Phase I sits at 6.7% based on 2014–2023 data. Every extra remediation cycle burns cash, delays launch, and compresses effective patent exclusivity.
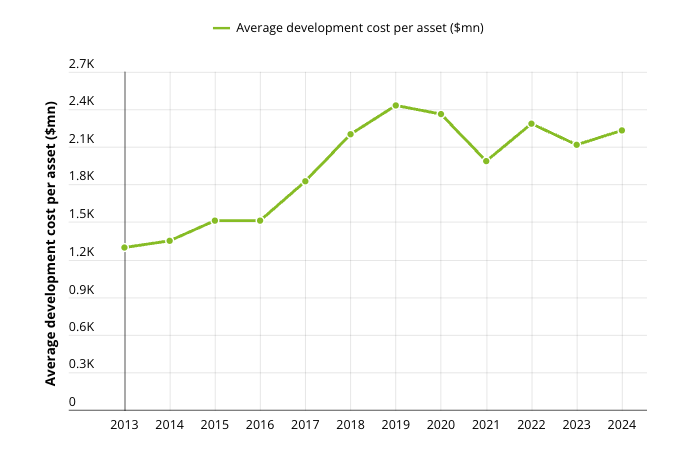
In that environment, understanding why things get delayed is often more valuable than understanding whether the science works. Most life sciences data products focus on positive events — approvals, trial starts, endpoint wins, licensing deals. CRLs are negative data with teeth. They tell you where the system breaks, and negative data is often more monetizable because it helps buyers avoid loss rather than chase upside.
The buyer set is wider than it first appears. Specialist biotech funds want to know which setbacks cost two quarters versus two years. CROs, CDMOs, and CMC consultants want to spot where remediation demand is about to spike — the biologics CDMO market alone was valued at roughly $25 billion in 2025 and is projected to exceed $38 billion by 2031. BD teams want to know when distressed assets become partnerable. Insurers, royalty financiers, and structured-credit players want better tools for underwriting timeline risk.

The FDA itself validated this demand when it published the dataset. The openFDA platform states that releasing CRLs helps developers "avoid blind alleys and common missteps" and "accelerate development." The regulator is telling the market these letters contain reusable operational learning. Build the product that organizes it.
The Play
The right product is not a searchable CRL archive. That's a feature, and anyone with an API key and a weekend can build a search tool over openFDA.
What works is a Regulatory Delay Intelligence Layer — a tool that converts messy rejection text into standardized, benchmarkable, decision-grade signals:
- What deficiency category was cited?
- Which modality was involved?
- Which sponsor profile tends to trigger this issue?
- How often does this problem recur?
- What remediation path usually follows?
- How long does that class of problem typically delay approval?
- Which vendors, consultants, or manufacturing capabilities become relevant when this issue appears?
That last question is where the economics shift. CRLs are not only regulatory documents. They're indirect demand signals for outsourced services.
When a cluster of CRLs points to assay validation problems in cell therapy, that's a go-to-market story for specialist analytics vendors. When repeated biologics CRLs center on facility, process, or comparability issues, that's a capacity-planning signal for CDMOs and CMC advisors. When certain sponsor archetypes repeatedly get hit on clinical design or statistical shortcomings, that's a prospecting list for regulatory strategy firms.
The wedge is data. The monetization is workflow, prioritization, and risk pricing. If you've been looking for a regulatory technology startup idea or a micro SaaS concept in life sciences, this is the kind of narrow vertical where a focused team can build real pricing power.
Why Incumbents Haven't Already Won This

Pharma intelligence is crowded. IQVIA, Clarivate (Cortellis), Citeline, Evaluate, and GlobalData already sell pipeline, trials, competitive intelligence, and market forecasting. Their products are broad, expensive, and optimized for commercial pipeline visibility. None of them have built a purpose-built product around converting a fresh public stream of FDA failure reasons into narrow delay benchmarks.
A focused startup can win here for four reasons.
The dataset is genuinely new. The 2025 releases created a normalization problem nobody has owned yet. The CRLs are public but messy — heavily redacted for trade secrets and personal information, spanning multiple review centers and years with evolving formats. The FDA hasn't even clarified how it applied redactions or whether its AI tool "Elsa" was used in the process. That messiness is your moat material.
The moat is taxonomy, not access. Build the best classification system for CRL deficiencies, remediation paths, sponsor archetypes, and modality-specific failure patterns, and you create durable intellectual property on top of public text. Anyone can read the letters. Very few can organize them into decision-ready benchmarks.
The customer doesn't need perfect coverage. A hedge fund focused on small-cap oncology needs credible delay benchmarks in its slice. A cell-therapy CDMO needs visibility into where sponsors are likely to get stuck. Neither requires a universal biotech graph.
The go-to-market can start with services disguised as software. Several strong vertical data companies followed this path: Preqin in private equity, PitchBook in venture. Sell research and analysis first, then productize the data layer underneath.
Three Levels of the Business
Level 1: Delay Database
Start with the obvious product: a cleaned, searchable CRL intelligence platform. Follow the following schema:
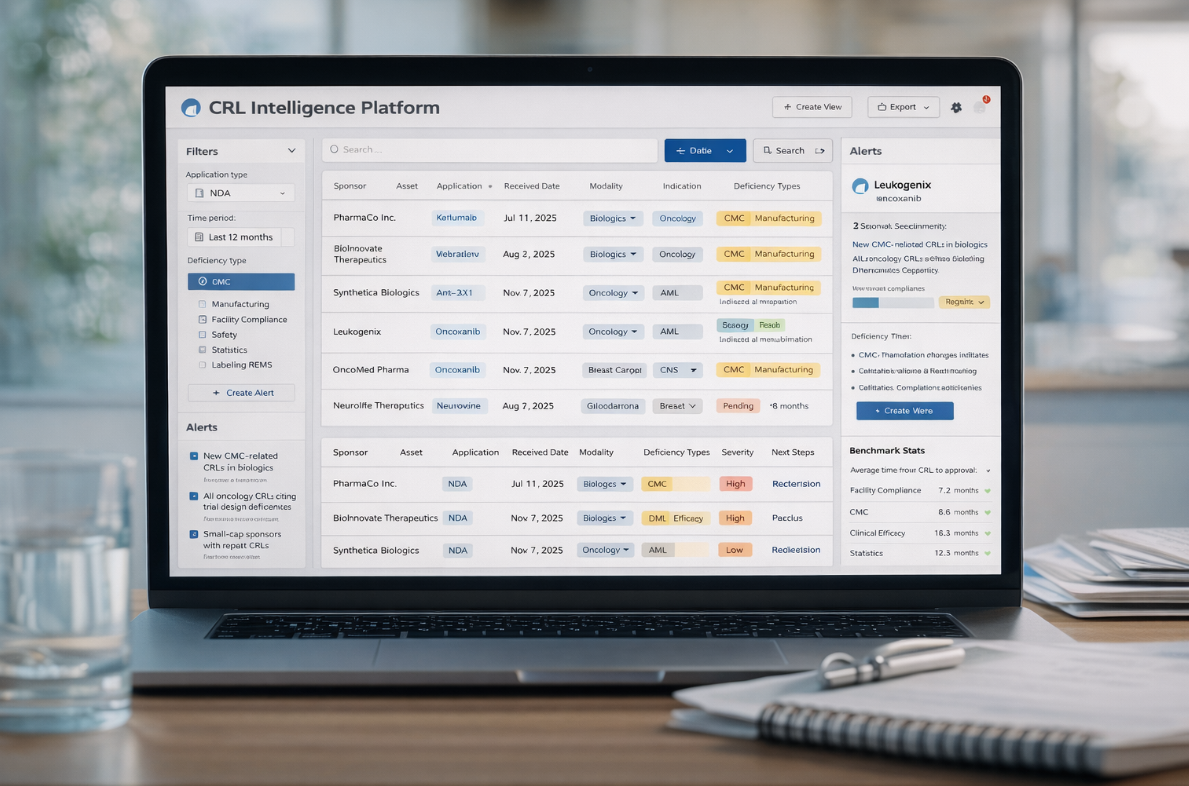
Unlock the Vault.
Join founders who spot opportunities ahead of the crowd. Actionable insights. Zero fluff.
“Intelligent, bold, minus the pretense.”
“Like discovering the cheat codes of the startup world.”
“SH is off-Broadway for founders — weird, sharp, and ahead of the curve.”





