

















Inside a self-driving lab, a team used an LLM to generate 300,000 structured driving scenarios—each validated with constraints and simulation rollouts—then shipped a 100,000-question reasoning benchmark alongside it.
Most people will skim that paper and file it under "neat autonomous-driving dataset."
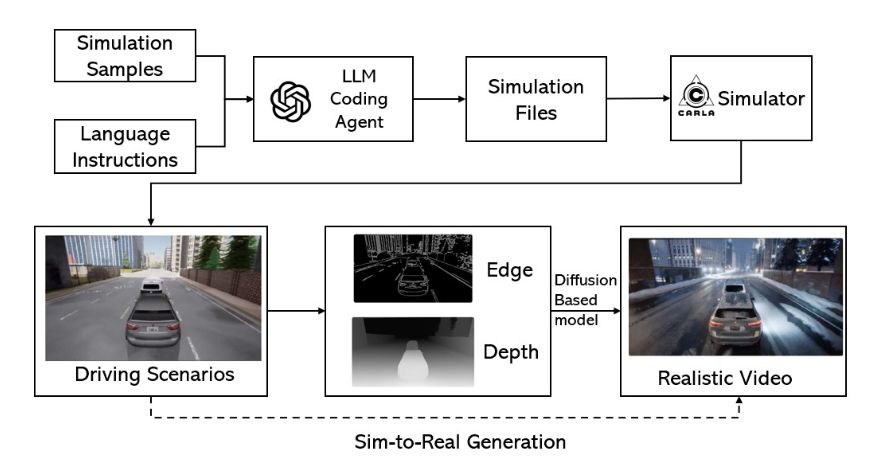
Here's what they're missing: this is the blueprint for how regulated industries will train—and govern—AI agents. The method ports cleanly to workflows where companies bleed money, lawsuits, and reputation: insurance claims, chargebacks, HR investigations, compliance audits, medical billing, prior authorizations. Get it right and you're looking at $60k-$150k annual contracts selling what amounts to infrastructure—the safety gate every AI agent has to pass before touching production.
Driving is just the pilot program. The real product is the constraint-validated engine itself.
The play
Start with Scenario Factory—targeting insurance claims + fraud or chargebacks—and sell it as three interlocking pieces:
- A benchmark + eval suite — the test that gates releases
- A scenario generator — the treadmill that never runs out of edge cases
- A governance layer — the CI/CD check that blocks bad agents from shipping
You're not "making synthetic data." You're building the safety gate for high-stakes AI decisions—where every new model, prompt tweak, policy change, or vendor swap gets run through the same adversarial gauntlet before touching production. Tools are commodities. Infrastructure is a moat.
Why now
Synthetic data crossed from curiosity to strategic infrastructure. The market grew from roughly $300-500 million in the mid-2020s to hit $450-500 million in 2025, and is tracking toward $2.6-9 billion by 2030—a 30-40%+ CAGR. More telling: NVIDIA acquired Gretel in March 2025 at a price above its prior $320 million valuation. When NVIDIA pays a premium for evaluation and privacy layers, the signal is clear: this stuff is foundational.
Everyone is shipping agents into liability zones—without proper tests. Recent surveys show 57% of organizations have AI agents in production, but 32% cite quality as their top deployment barrier. An estimated 85% of AI projects fail to deliver promised value, and 80% of organizations report their agents are "misbehaving, leaking data, or hallucinating information." Only 52% run offline evaluations on test sets. The gap between deployment speed and testing rigor is massive—and dangerous.
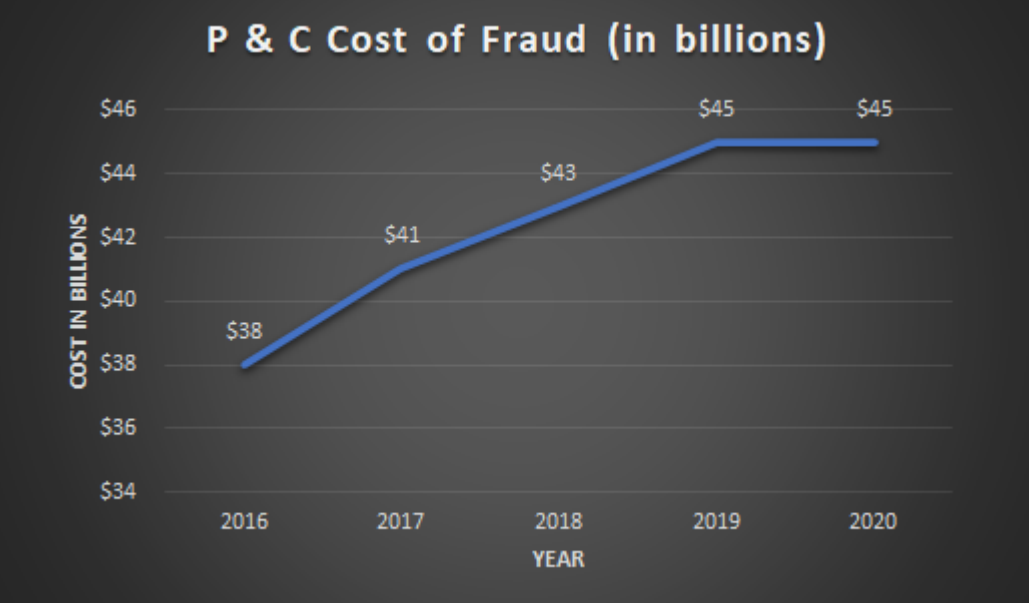
The costs of getting it wrong are staggering. Insurance fraud alone costs the U.S. economy over $308 billion annually, with property and casualty fraud accounting for $45-122 billion—roughly 10% of P&C loss and adjustment expenses. In payments, chargebacks will cost eCommerce $33.79 billion in 2025, projected to hit $41.69 billion by 2028. Here's the killer: every dollar of chargeback fraud costs merchants $4.61 in total impact (fees, operations, false declines). Friendly fraud—where legitimate customers file false disputes—drives 70-75% of these cases.
The dirty secret: pure synthetic loops can rot models. Model collapse from recursive synthetic training is real—peer-reviewed research shows AI models degrade when trained exclusively on generated data. But the same research shows that verification and filtering layers can make synthetic retraining beneficial in controlled regimes. Your pitch must be evaluation-first, constraints-first, designed to mix real incident patterns with synthetic coverage. You're not replacing real data—you're systematically covering the tail.
The insight
Most synthetic-data vendors sell data.
You sell the right to ship.
"We define the canonical test suite for your workflow. If your agent can't pass it, it doesn't go live."
The AgentDrive blueprint is dangerous precisely because it's built around a factorized scenario space (orthogonal axes like weather, road type, traffic density), structured generation (tuples → full scenarios), constraint validation (schema + domain rules), and objective labels (expected outcomes + rubrics). This isn't a dataset—it's the skeleton of a benchmark.
Where you win
You're not competing with "another AI agent startup." You're stitching gaps across three adjacent categories:

Unlock the Vault.
Join founders who spot opportunities ahead of the crowd. Actionable insights. Zero fluff.
“Intelligent, bold, minus the pretense.”
“Like discovering the cheat codes of the startup world.”
“SH is off-Broadway for founders — weird, sharp, and ahead of the curve.”





