
















Think generative engine optimization meets brand intelligence, built for one high-stakes category where attribute errors cost real revenue.
Enterprise platforms already charge $3,000–$15,000/month for horizontal dashboards. A small team targeting a single vertical with a service-backed product can realistically reach six-figure MRR from 10–20 clients — while assembling the proprietary intervention-outcome dataset that makes the software defensible long-term.
Search is not dead. It is being split into two layers.
The first layer is still Google: links, clicks, rankings, intent capture. The second layer is the model layer. ChatGPT, Gemini, Claude, Perplexity, and AI Overviews now decide which brands enter the conversation before a user ever sees a link. Gartner predicted traditional search volume would drop 25% by 2026 as AI chatbots absorbed discovery behavior. That prediction is landing.
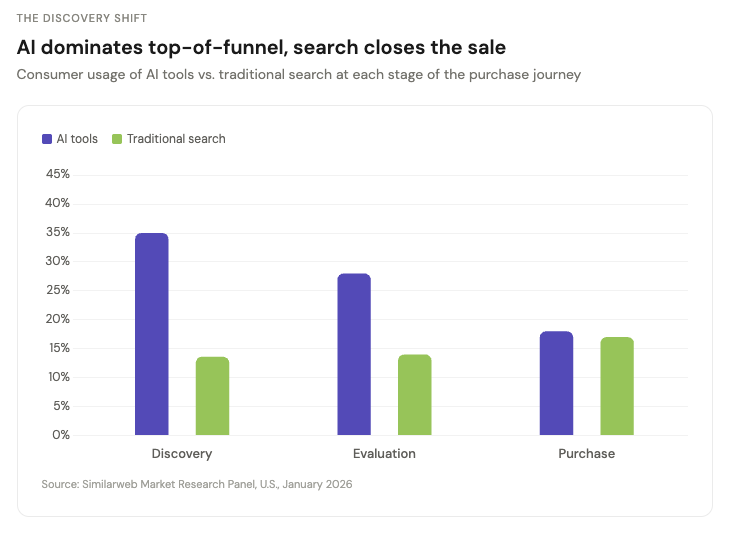
The sharper data came in March 2026. Similarweb's GenAI Brand Visibility Index found that 35% of U.S. consumers now use AI tools at the product discovery stage, versus just 13.6% who use traditional search. At evaluation, AI holds a 2:1 advantage. The gap only closes at the final purchase step.
AI owns the top of the funnel. Search closes the sale. If your brand is invisible in AI responses, you are absent from discovery for more than a third of potential customers before any intent signal reaches Google.
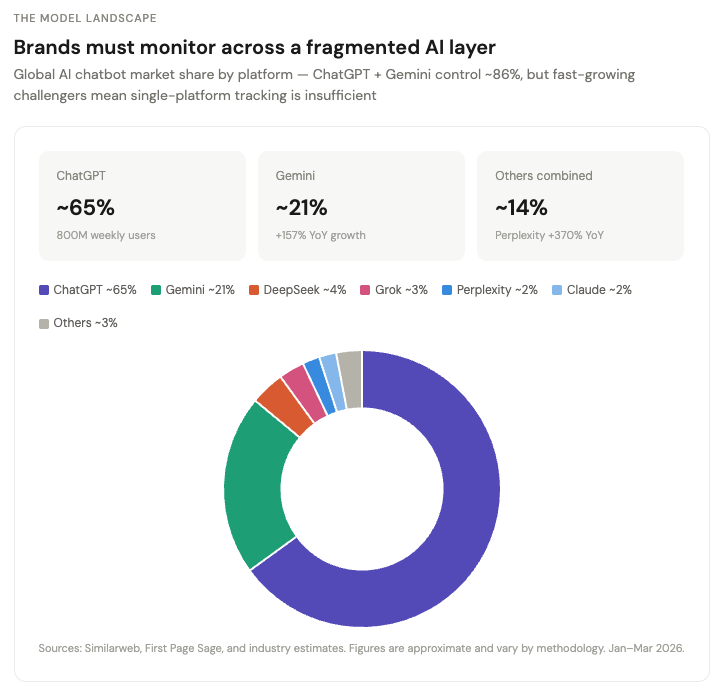
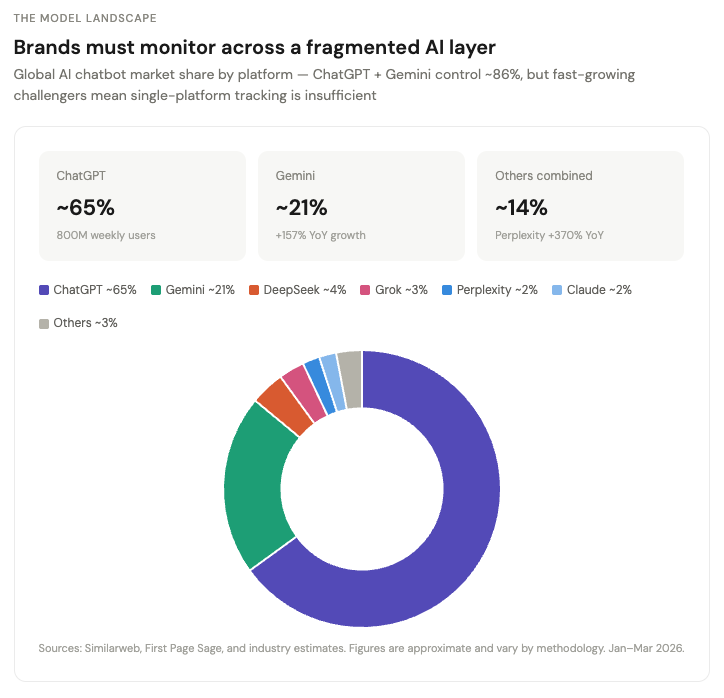
This is already a budget line. Conductor's research shows a sizable share of digital marketing leaders now rank generative engine optimization as their top priority for 2026, with meaningful portions of digital budgets already reallocated. Adobe, Semrush, Meltwater, and Similarweb are all selling products around AI visibility. But the real startup opportunity is not "ChatGPT rank tracking." That is the toy version. The real business — and a genuine B2B SaaS idea for marketers, brand strategists, and SEO leads — is brand narrative control in answer engines. Evertune charges $3,000/month per brand. Profound commands $4,000–$15,000/month at enterprise tiers.
Start with 10–20 clients and you are building a six-figure MRR base while collecting the data that turns your software into a moat.
When someone asks an LLM, "Which payroll platform is best for a 50-person startup?" the model compresses the public internet into a recommendation. It synthesizes product pages, review sites, Reddit threads, comparison articles, and forum complaints into a single answer. If it misclassifies you, omits you, or frames you with the wrong attributes, consideration changes before the click.

Let's say you run a mid-market B2B software company. You sell to small startups. Your positioning is "simple, fast, affordable." But a two-year-old Gartner comparison article described you as "enterprise-focused" and a stale G2 review mentioned "complex onboarding." Those two sources get compressed into a characterization that excludes you from the shortlist entirely. Your homepage copy is irrelevant. The model is reading the internet's version of your brand, and nobody on your team knows it.
SEO had rankings.
Social had share of voice.
AI discovery needs its own metric.
Executives get it immediately: when people ask AI about your category, how often do you show up, how prominently, with what positioning, and sourced from where?
Why the window is opening now
Answer engines do not behave like neutral directories. BrightEdge data found that Google AI Overviews were more likely to surface negative brand sentiment than ChatGPT. They compress narratives. They over-weight old complaints, third-party reviews, and badly structured product pages. The risk is not just invisibility. It is mispositioning at machine scale.
Commerce is layering on top. OpenAI launched Instant Checkout — powered by Stripe's Agentic Commerce Protocol — letting users buy directly from Etsy sellers inside ChatGPT, with over a million Shopify merchants coming soon. Product results are organic and unsponsored, ranked on relevance. EMARKETER projects tens of millions of U.S. shoppers will use AI chatbots during the purchase process in 2026. Early signals from major retailers show ChatGPT referral traffic growing rapidly month-over-month. OpenAI has confirmed ads are coming.
Think about that sequence. This is early Google. Organic visibility today means dominant positioning when the paid auction opens.
The competitive landscape, and the gap worth exploiting
This space is filling up fast.
On the enterprise end, Evertune (founded by Trade Desk veterans, $19M in funding) charges $3,000/month and runs 1M+ AI prompts per brand monthly across 10+ engines. Profound ($35M from Sequoia) runs over 6 million prompts daily and positions itself as the enterprise-grade, compliance-ready platform. Adobe's LLM Optimizer sits alongside its existing marketing stack. These companies are building horizontal dashboards for Fortune 500 brand teams.
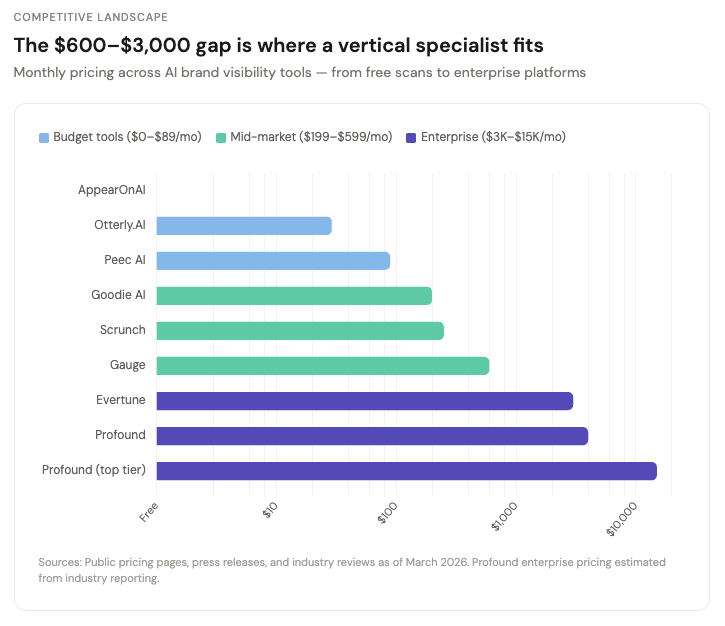
Mid-market tools are multiplying. Scrunch ($250/month), Goodie AI ($199/month), and Gauge ($99–$599/month) serve growing marketing departments with different angles: discovery path mapping, e-commerce focus, and competitive intelligence, respectively.
Budget entry points already exist too. Otterly.AI starts at $29/month, Peec AI at €89/month, and AppearOnAI offers a free scan feature.
So where does a small team — or a solo founder building AI-powered SaaS tools — find an opening?
The gap is in three places.
Vertical depth. Nearly every player listed above is horizontal. They sell to "marketers" broadly. The underbuilt opportunity is going narrow into categories where a wrong AI answer has disproportionate revenue consequences. Alcohol and spirits. Supplements and wellness. Financial products. Legal services. Luxury goods. Healthcare. In these verticals, the difference between being described as "premium" versus "budget," or "clinically proven" versus "unverified," directly moves revenue. A generic monitoring tool does not know that. A vertical specialist does. Princeton's GEO research confirms this: what works varies meaningfully by domain, which means vertical-specific playbooks compound in value over time.
The remediation workflow. The vast majority of current tools stop at monitoring. They show you what AI says about your brand. That is a feature. The harder, more valuable build is the full loop: diagnose why the model says what it says, identify which source nodes are driving the narrative, prescribe specific fixes, execute those fixes, and measure whether they changed the model's output over time. That feedback loop is where the real moat lives. Nobody owns it yet.
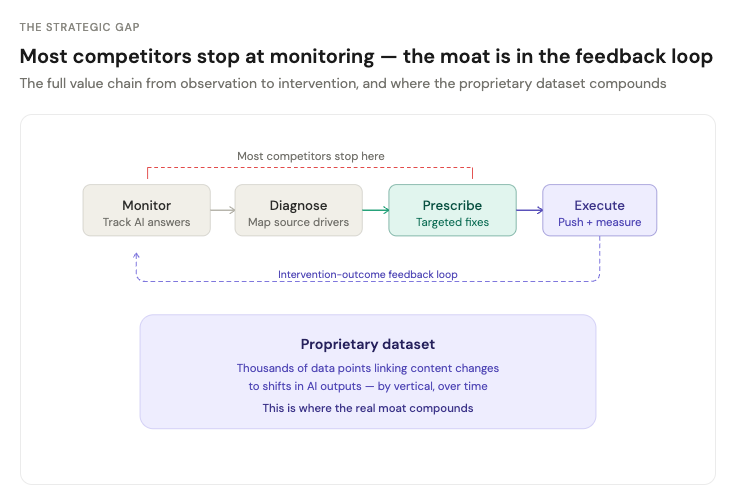
The intervention-outcome dataset. Every tool can call an API and store outputs. There is no moat in that. The moat is in collecting thousands of data points linking specific content interventions to changes in AI outputs across models, over time, within a vertical. If you know that updating a specific comparison page improved Brand X's Share of Model score by 14% over six weeks in the supplements category, that knowledge compounds. After a year of that data, you have a proprietary causal map that no competitor can replicate without doing the same work.
The wedge: from gimmick to painkiller
The bad version of this startup is a dashboard that runs prompts every morning and shows whether your brand appeared. That gets copied in a weekend.
The better version is an AI narrative observability layer for brands. Monitor, diagnose, prescribe, execute.
Job 1: Monitoring. You ask the same family of questions across models, personas, geographies, and time. You log mention frequency, prominence, citations, sentiment, and attribute alignment. The question is not "were we mentioned?" It is "were we described as premium, safe, budget, innovative, enterprise-ready, or clinically validated?" This is where Share of Model becomes useful, because it lets you score visibility at the attribute level.

Job 2: Diagnosis. Why is the model saying this? Which sources are being cited? Which competitor pages are shaping the comparison set? Which review sites, Reddit threads, listicles, stale product pages, or schema gaps are dominating the narrative? Most founders miss a key insight here: this is an entity-and-source problem as much as a copywriting one. Brands need to optimize both on-site content and the off-site sources that LLMs rely on.
Job 3: Prescription. What exactly should the brand change? Which pages need clearer comparisons? Which FAQs need explicit attribute language? Which third-party profiles need cleanup? Which structured data is missing? Which topics require authoritative off-site validation? This is where the product stops being a monitor and starts becoming a workflow engine.
Job 4: Execution. Push the fixes into Webflow, Shopify, WordPress, or a PR workflow. Generate publish-ready briefs. Create change tickets. Measure whether the changes improved Share of Model over the next 2–8 weeks. This is where you build the moat, because you are assembling a proprietary dataset linking interventions to answer-engine outcomes.
The insight
The obvious read is "SEO for ChatGPT." That framing is too small.
This is a new form of brand infrastructure sitting at the intersection of SEO, PR, product marketing, and reputation management. SEO teams think in pages and keywords. PR teams think in narratives and external mentions. Product marketers think in positioning and category claims. LLMs collapse all three into one answer. That creates genuine organizational pain, because nobody fully owns the machine's version of the brand.
The winning product here is sold as a cross-functional control plane for the AI-facing brand.
That distinction matters for go-to-market, because the fastest path to budget is one of three concrete pitches:
Risk prevention. Stop harmful or inaccurate machine narratives before they spread. A supplement brand gets flagged as "unproven" across every LLM because of one FDA warning letter from 2021. That kind of damage compounds silently.
Competitive intelligence. Show leadership where competitors dominate the model layer. Your competitor shows up in 7 out of 10 AI responses for your core buying queries. You show up in 2.
Demand capture. Improve AI-sourced inclusion in consideration sets. When ChatGPT recommends running shoes, your brand appears with the attributes that matter to your target buyer.
Those are boardroom-ready pitches. "Prompt tracker" is not.
What the product should actually be
Call it Share of Model OS.
The platform has five modules:

Unlock the Vault.
Join founders who spot opportunities ahead of the crowd. Actionable insights. Zero fluff.
“Intelligent, bold, minus the pretense.”
“Like discovering the cheat codes of the startup world.”
“SH is off-Broadway for founders — weird, sharp, and ahead of the curve.”





