


















A grad student spent six months building novel machine learning architecture. Published in NeurIPS. Got 47 citations in a year. Total commercial impact: zero.
The problem isn't the research. It's what happens after "Submit."
Right now, researchers ship PDFs into a void. Their work lands in academic journals, gets indexed by Google Scholar, and mostly dies there. Less than 15% of published academic work ever reaches practitioners who could actually use it. The insights exist. The applications exist. But nothing connects them.
OpenAI just lit the fuse on a fix.
On January 16, 2026, they released Prism, a free, cloud-based LaTeX workspace with GPT-5.2 embedded directly into the document. Real-time collaboration. Voice-based editing. Automatic citation management. No local installation, no environment hell, unlimited collaborators.
Prism isn't trying to be another Overleaf. It's positioning as the default authoring layer for research—the Google Docs moment for scientific work. And that matters because when a tool becomes where people already do the work, every workflow that happens after becomes a business opportunity.
Research is about to become a product category, not just an output format.
The opportunity: build the layer that comes after Prism. Build the "Publish Pack"—a pipeline that turns ML research papers into distribution-ready assets. Landing page with claim provenance, conference talk deck, model card, interactive demo scaffold. Everything an ML researcher needs to go from "paper accepted" to "impact delivered."
Start with ML researchers who already expect these outputs and face hard requirements.
Individual researchers pay $49-$99/pack or $29-$79/month for unlimited generation.
Lab subscriptions run $399-$999/month.
Institutional licenses scale to $10K-$100K/year.
Capture 1,000-1,500 paying researchers in year one and you're at $50K-$100K MRR.
Why this window exists right now
Prism just standardized the input layer for scientific authoring. Built on Crixet (a cloud LaTeX editor OpenAI acquired), it's free, collaborative, and has GPT-5.2 embedded. When one tool owns creation, downstream workflows become predictable: consistent LaTeX structure, BibTeX citations, figure organization. That predictability enables automation.
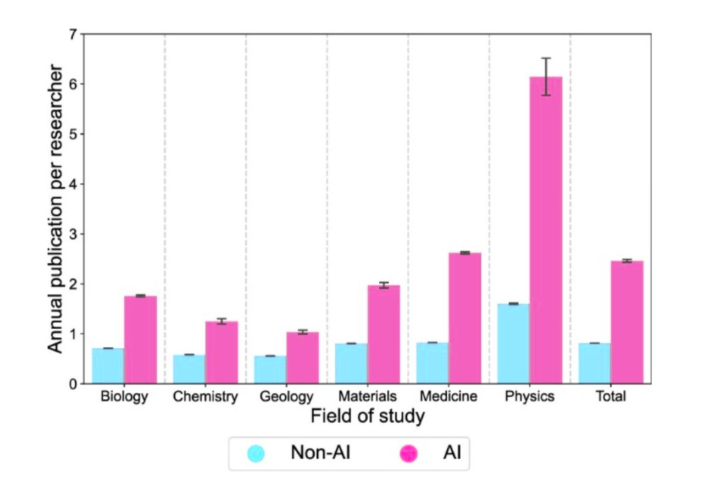
AI adoption in research is already mainstream—a Nature-published study analyzing 41.3M papers found AI-using scientists publish 3x as many papers and receive 4.8x as many citations. Researchers aren't asking "should I use AI?" They're asking "how do I package all this output?"
Right now, that packaging is fragmented. Researchers paste figures from papers into PowerPoint, hand-write model cards, skip demos because they don't know web frameworks. Prism consolidated authoring. The next consolidation is distribution—turning finished papers into the assets that actually drive impact.
The "paper dies as PDF" problem is acute and obvious
Academia's distribution problem isn't hidden. It's discussed openly in every research methods seminar, every grant proposal, every impact statement.
Practitioners engage with less than 15% of published academic work. Not because they don't care—because the format is hostile. A 40-page NeurIPS paper written for peer reviewers doesn't translate to a 20-minute talk for industry engineers. A methods section optimized for reproducibility doesn't become a landing page that converts GitHub visitors into collaborators.
The translation layer doesn't exist. Researchers who want broader impact have three options: hire a science communicator (expensive, slow), learn to build these assets themselves (time they don't have), or don't bother (what usually happens).
A tool that generates research-native packaging—outputs structurally designed for research, where claims stay precise, caveats survive translation, and audiences can trust provenance—would slot directly into an existing, painful workflow gap.
The wedge: ML research first, where requirements already exist
If your product is "upload PDF, get presentation," you're roadkill in six months. Google Slides has AI features. Gamma exists. Canva is iterating fast. Generic tools will commoditize generic outputs.
The defensible wedge is ML/AI research—the one domain where packaging isn't optional, it's required.
NeurIPS, ICML, and ACM now mandate model cards for paper acceptance. Dataset documentation follows standardized schemas (Datasheets for Datasets, Model Cards for Model Reporting). Conferences expect reproducibility artifacts: code repositories, trained models, demo interfaces. The field has already normalized the outputs you're generating. You're not creating demand—you're automating compliance.
ML researchers already ship demos to HuggingFace. They maintain GitHub repos. They write model cards answering 30-50 structured questions about training data, evaluation procedures, failure modes, limitations. A tool that generates these from their LaTeX source doesn't have to convince them these assets matter—it just has to save them 6-8 hours per paper.
Generic doc converters can't do this. They don't know which sections map to "Training Data" vs. "Evaluation Protocol." They don't auto-extract test cases for demo inputs. They don't flag when a claim in a landing page overclaims relative to the evidence in Section 4.2.
The moat isn't templates. It's epistemic infrastructure: provenance tracking, limitation-first defaults, field-specific norms baked into every output.
The ML Publish Pack: four assets researchers already need
From one Prism project, generate:

Unlock the Vault.
Join founders who spot opportunities ahead of the crowd. Actionable insights. Zero fluff.
“Intelligent, bold, minus the pretense.”
“Like discovering the cheat codes of the startup world.”
“SH is off-Broadway for founders — weird, sharp, and ahead of the curve.”





